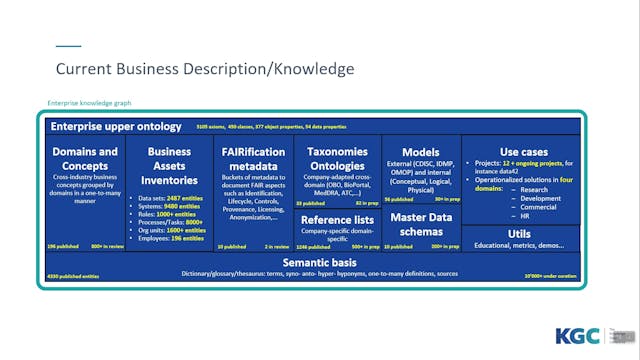
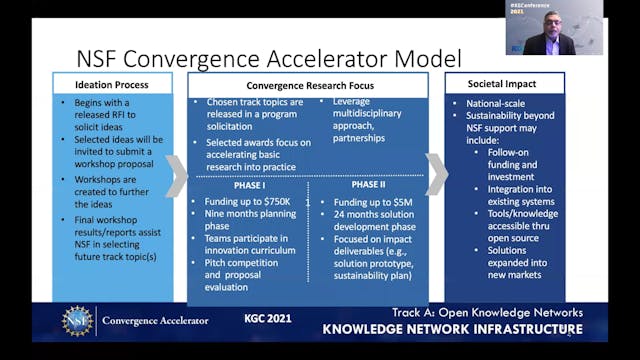
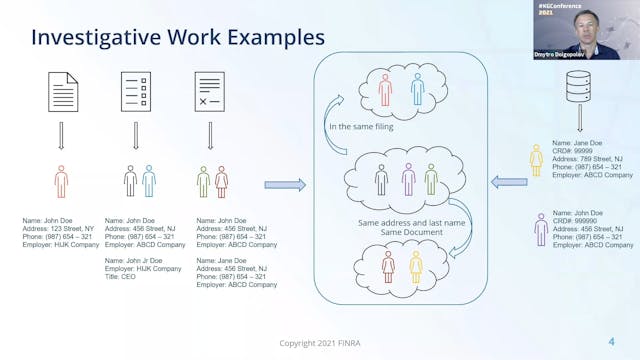
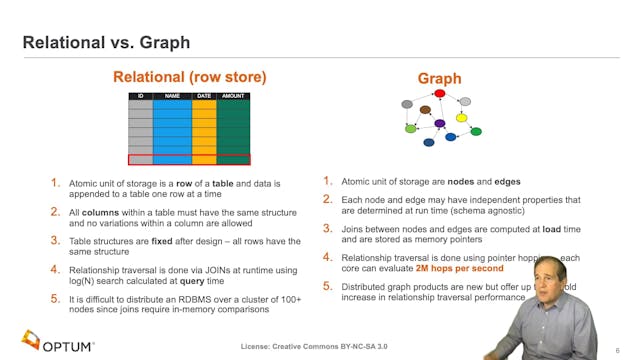
-
Martynas Jusevicius | Data-centric Transformation
One of the key pieces of global infrastructure today is the web yet it continues to be developed using legacy technologies dating back to the 1960s. A result of using outdated technology in turn has created several major problems. First, relational data models are a primary contributor to the dat...
-
Maulik Kamdar | Elsevier's Healthcare Knowledge Graph
Knowledge Graphs are increasingly being developed and leveraged in academia and industry to tackle complex biomedical challenges, such as drug discovery and safety, medical literature search, clinical decision support, and disease monitoring and management. In this talk, we will present the resea...
-
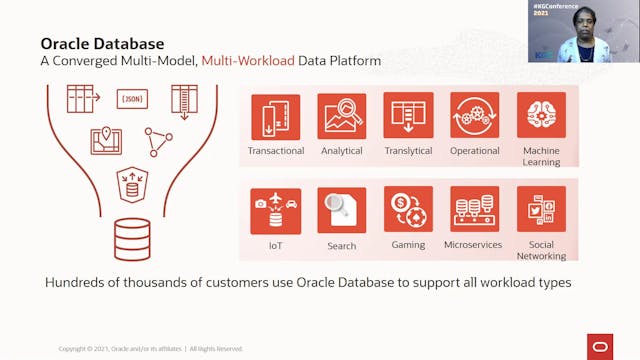
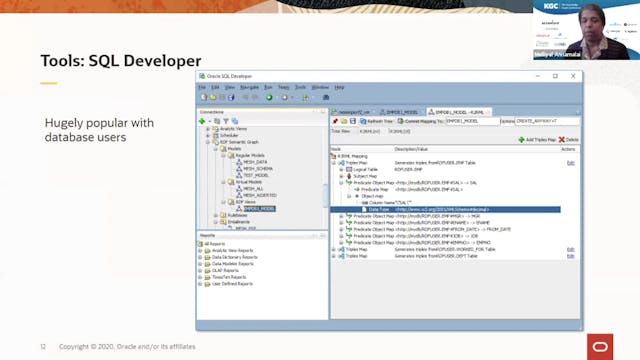
Melliyal Annamalai | Developing Enterprise Applications With Oracle Graph
Application developers often need to work with a variety of data types, data models, and workloads within an application. Oracle Database is a multi-model, multi-workload data platform with model-specific tools and technologies, enabling developers to build integrated applications while taking a...
-
Michael Cafarella | Infrastructure For Knowledge Graph Application Programming
Social Knowledge Graphs such as Wikidata have become massive successes, obtaining a level of coverage and quality that would be the envy of many traditional relational database engineering projects. And yet the downstream use scenarios for such datasets remain sharply limited compared to the vast...
-
Mike Tung | Automated Knowledge Graphs For Market Intelligence
Nearly every business is constantly trying to identify, analyze, and grow their market. Yet, traditional processes for data management inevitably lead to a database that contains missing, outdated, invalid, or inconsistent data. Automated knowledge graph construction techniques are a scalable w...
-
Mike Welch | Serving A Web Scale Knowledge Graph
The Yahoo Knowledge Graph powers entity data for user experiences across multiple products at Verizon Media, from search to media to ads. Nodes in the knowledge graph correspond to real world entities: people, places, movies, sports teams, and so on. The edges represent semantic relationships bet...
-
Mohammed Aaser | Future Of Enterprise Data Management
Many organizations have initiated data and analytics transformations with some success, however are beginning to face challenges in scaling efforts beyond a handful of applications/use cases. One of the major barriers remains around data management, including challenges with data transparency, i...
-
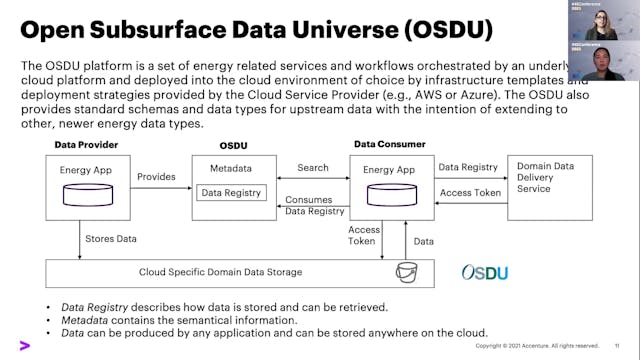
Neda Abolhassani & Teresa Tung | Accelerating Industry Data Integration
A data supply chain is industry-specific, but many data prep tools are industry agnostic. As part doing this work, data engineers and domain experts apply their deep knowledge of how to transform raw data to a form that can address specific problems. In this way, the data supply chain is a doma...
-
Olaf Hartig | RDF Star: Metadata For RDF Statements
The lack of a convenient way to capture annotations and statements about individual RDF triples has been a long standing issue for RDF. Such annotations are a native feature in other contemporary graph data models (e.g., edge properties in the Property Graph model). In recent years, the RDF* app...
-
Paco Nathan | Graph Based Data Science
Python offers excellent libraries for working with graphs: semantic technologies, graph queries, interactive visualizations, graph algorithms, probabilistic graph inference, as well as embedding and other integrations with deep learning. However, most of these approaches share little common groun...
-
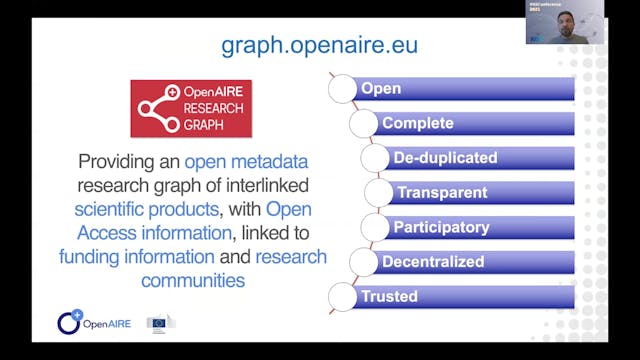
Paolo Manghi | The OpenAIRE Research Graph: Science As A Public Good
The presentation will introduce the motivations, architecture, and operation of the OpenAIRE Research Graph (http://graph.openaire.eu), one of the largest (if not the largest) public, open access, collections of metadata and semantic links (~1Bi) between research-related entities: articles (124M+...
-
Peter Hicks | Visualizing Data Lineage
Extracting metadata from data pipelines and building useful graphs for real production environments.
-
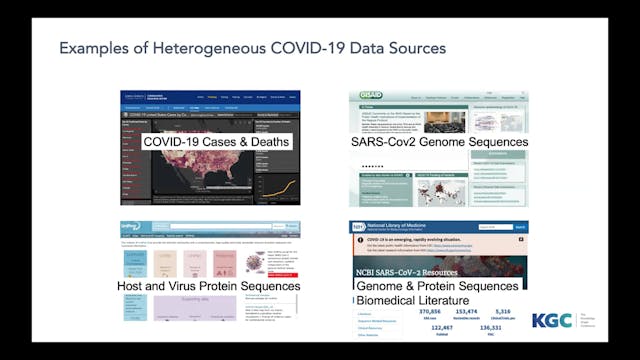
Peter Rose | Integrating Heterogeneous Data Sources Into A COVID-19 Graph
The COVID-19 pandemic has mobilized researchers worldwide to investigate many aspects of the outbreak, ranging from case statistics, patient demographics, transportation modeling, epidemiological studies, to viral genome sequencing. Relevant data are produced and publically shared at an unprecede...
-
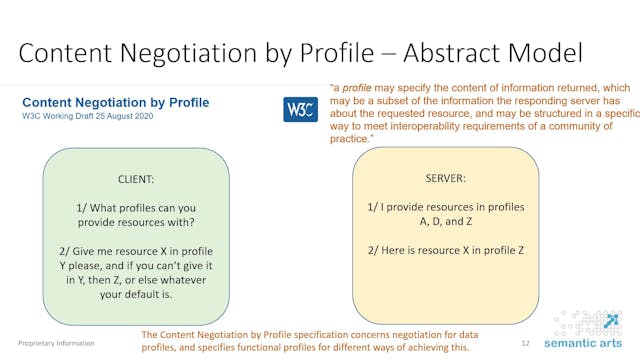
Peter Winstanley & Boris Pelakh | W3C Dataset Exchange Group
This presentation will introduce and detail the current work of the W3C Dataset Exchange Working Group, including detail of the developments in the DCAT (Data Catalog) vocabulary and the proposal for content negotiation by profile (ConnegP) which is being developed by the working group in conjunc...
-
Ridho Reinanda | Financial Knowledge Graph At Bloomberg
The Bloomberg Knowledge Graph is a graph-centric representation of entities and relationships in the financial world which connects cross-domain data from various sources within Bloomberg. Recent developments in machine learning, knowledge graphs, and language technology have enabled intelligent ...
-
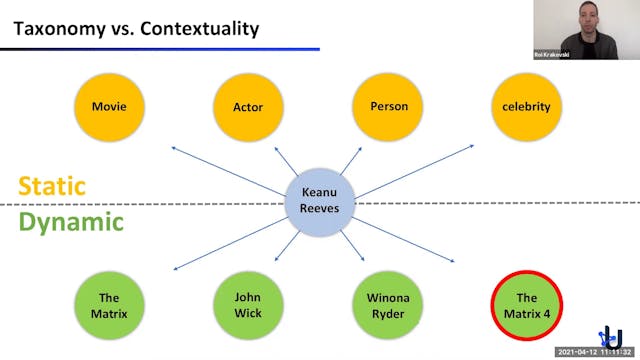
Roi Krakovski | The Usearch Contextual Graph
We exploit the recent breakthroughs in Neuroscience to build web search engines based entirely on AI-generated data, thus eliminating the need to collect users’ data. We show how to generate search queries that are almost identical to real users’ queries. We use the generated queries to build a ...
-
Ryan Wisnesky | How To Optimally Merge Knowledge Graphs With Category Theory
In this talk we describe a new technique for merging knowledge graphs: translating the knowledge graph schemas into categories and the knowledge graph data into functors, then applying the "co-limit/pushout" construction from a branch of mathematics called category theory to merge these categorie...
-
Sergio Baranzini | SPOKE: A Biomedical Open Knowledge Graph
SPOKE is a biomedical knowledge graph containing factual data on various biomedical fields including genetics, molecular biology, physiology, metabolomics, pharmacology and clinical medicine. SPOKE can be used to repurpose medications, predict patient outcomes, and accelerate drug development, am...
-
Shekhar Iyer | Multi-Modal Retrieval Over Knowledge Graphs
Recent Advances in representation learning and application of Deep Neural Nets towards structured data and Knowledge Graphs (KG) is enabling opportunities for multi-modal representation of entities and relations. We can now aspire to build access to data encoded in knowledge Graphs through one of...
-
Stefan Plantikow | The Upcoming GQL Standard
Following the GQL Manifesto, the ISO working group that develops the SQL standard voted to initiate a project for a new database language: GQL (Graph Query Language). This talk presents an overview of the goals of GQL and the progress so far, key aspects of the language design such as the basic d...
-
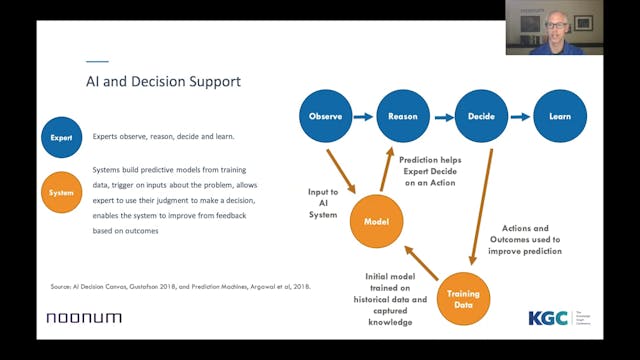
Steven Gustafson | Connecting The Dots With Knowledge & Data
Knowledge graphs provide a way for us to capture and relate information into a representation that can mimic expert knowledge. One type of expert knowledge that has proven to be particularly useful in industry is reasoning by analogy, or using a replacement problem and solution pair to think abo...
-
Trey Botard | Bringing Time & Truth To Semantic Data
Semantic systems provide tremendous opportunities to interoperate our data, facilitate shared vocabularies, and power enterprise knowledge graphs, but these increasingly distributed data ecosystems also introduce new instabilities and concerns. What happens when data we rely on is changing in une...
-
Veronika Heimsbakk | Tales From The Road Of Text To Knowledge
When transforming amounts of plain text into semantic knowledge graphs using Resource Description Framework, a service for automatic interpretation became apparent. Manual interpretation of text depends on human domain knowledge and discovery of entities and relationships in the text. This proces...
-
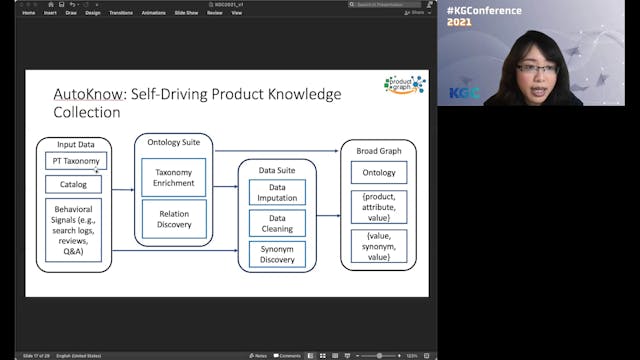
Xian Li | AutoKnow: Self-Driving Knowledge Collection For Products
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products
offered at online retail sites.... -
Ying Ding | Katana Graph Solutions: Scalable Graph Search & Graph Mining
When knowledge graphs in your company get larger and larger, a scalable graph search is in high demand. In the current graph search solutions, scalability is still a big issue. Furthermore, with the fast development of deep learning on graphs, many companies rely on deep learning methods to mine ...
-
Andreas Blumauer | The Semantic Content Hub: Transforming Data Hurdles
Ambiguity, language discrepancies, and lack of background information are just a few challenges that organizations face on a daily basis when trying to analyze their content and data. When an organization produces data that is hard to manage, what methodologies can be used to turn unstructured (i...
-
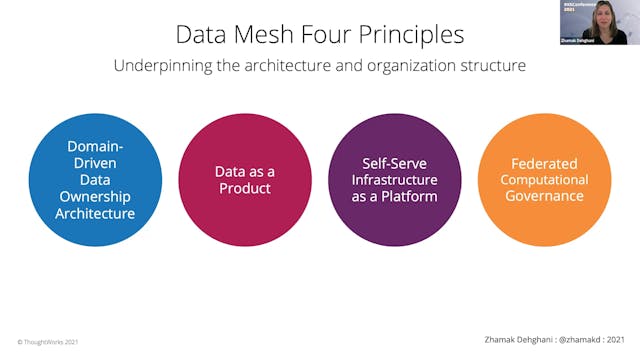
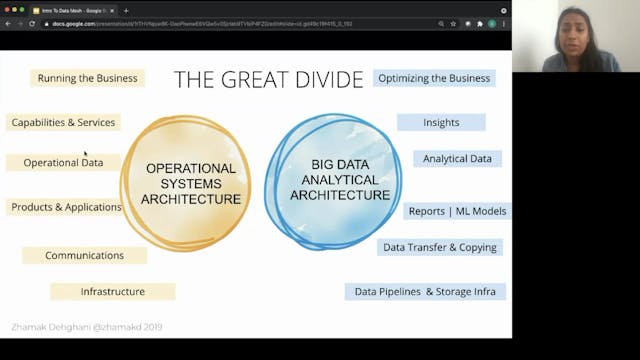
Zhamak Dehghani | Introduction To Data Mesh
For over half a century organizations have assumed that data is an asset to collect more of, and data must be centralized to be useful. These assumptions have led to centralized and monolithic architectures such as data warehousing and data lake, and neither of which have been able to enable data...
-
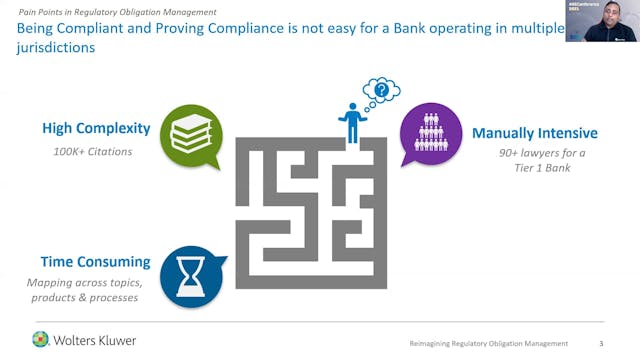
Abhishek Mittal | Re-Imagining Regulatory Obligation Management
Content Enrichment: Development and deployment of a 5-stage taxonomy. Applying the taxonomy to tag regulations and classify them for improved discovery & work assignment.
Smart Authoring: Leveraging advanced NLP and ML techniques to learn from the past content authoring for identification of ... -
Alena Vasilevich | Benefits Of Collaborative AI vs. Manual Creation
In the realm of data-driven businesses, structured data, being highly organized and easily understood by machines, is a valuable resource. IATE, with almost one million concepts storing multilingual terms and metadata, holds a large part of the textual knowledge of the EU. However, it can only be...
-
Alex Kalinowski | Structured To Unstructured & Back: Integrated KG and NLP
Identification of entities and the relations between them is a difficult task for traditional pattern-based matching or machine learning approaches; these techniques rapidly overfit training datasets and struggle to transfer to other contexts or domains. Utilizing outside knowledge, such as facts...
-
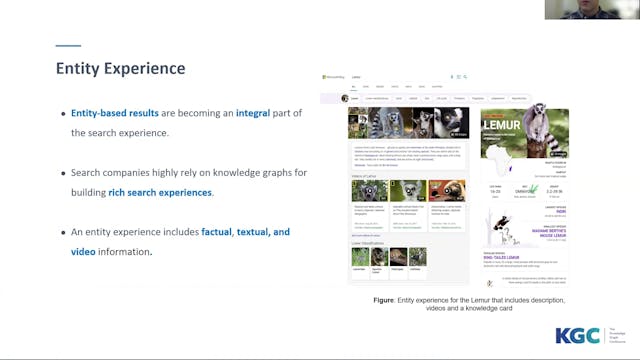
Amgad Madkour | Entity Life Cycle In Search-Centric Knowledge Graphs
Entity-based results are becoming an integral part of the search experience. Search-centric companies highly rely on knowledge graphs in providing the necessary information for building rich search experiences. An entity can originate from a structured, semi-structured, or unstructured data sourc...
-
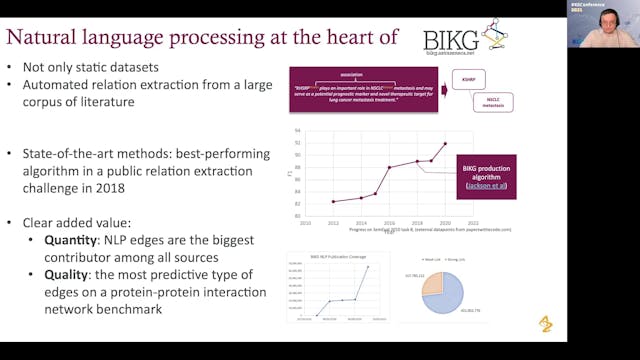
Andriy Nikolov | Biological Insights: Knowledge Graph To Help Drug Development
The use of knowledge graphs as a data source for machine learning methods to solve complex problems in life sciences has rapidly become popular in recent years. Our Biological Insights Knowledge Graph (BIKG) combines relevant data for drug development from more than 50 public as well as internal ...
-
Antonin Delpeuch | Scaling & Maintaining OpenRefine
OpenRefine is a data wrangling tool which celebrated its 10th birthday this year. Cleaning and importing data in knowledge graphs is its core use case, since it was originally designed to help populate Freebase. In this talk I want to give a broad overview of the latest developments in the tool a...
-
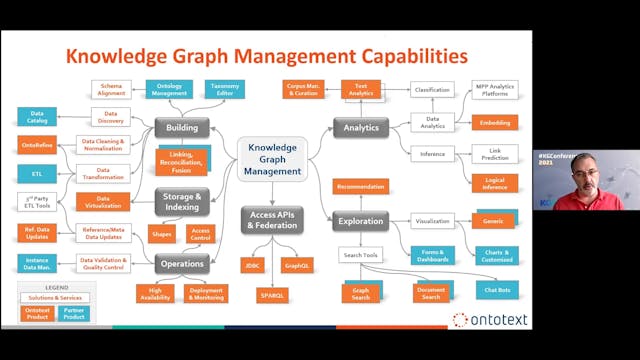
Atanas Kirakov | Knowledge Graph Magic Map: Capabilities & Partners
Ontotext teams up with portfolio partners to offer a complete platform with best-of-bread tools for: schema and taxonomy editing; data transformation and linking; access control and federation; data updates and validation; search and visualization. The ecosystem also includes global and regional ...
-
Barr Moses | Data Observability: The Next Frontier Of Data Engineering
To keep pace with data’s clock speed of innovation, data engineers need to invest not only in the latest modeling and analytics tools, but also technologies that can increase data accuracy and prevent broken pipelines. The solution? Data observability, the next frontier of data engineering. I'll ...
-
Ben De Meester | PROV4ITDaTa: Flexible Knowledge Graph Generation Within Reach
Personal Knowledge Graph generation is no longer a cumbersome technical endeavor. PROV4ITDaTa is an MIT open source platform to provide a smooth user experience for generating knowledge graphs from your online web services, such as Google, Flickr, and Imgur, into your personal data space. This br...
-
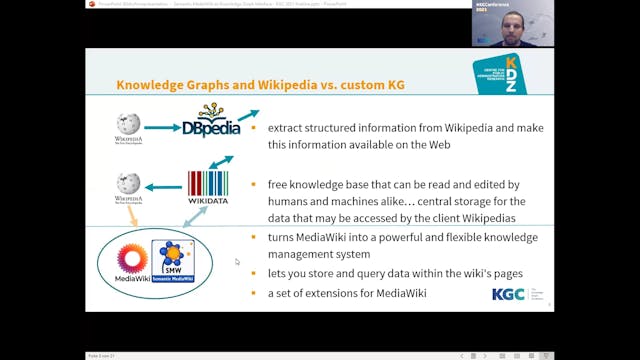
Bernhard Krabina | Semantic MediaWiki As Knowledge Graph Interface
Semantic MediaWiki (SMW), which was introduced as early as in 2006, has since gone on to establish a vital community and is currently one of the few semantic wiki solutions still in existence. SMW is an extension of MediaWiki, the software used for Wikipedia and many other projects, resulting in ...
-
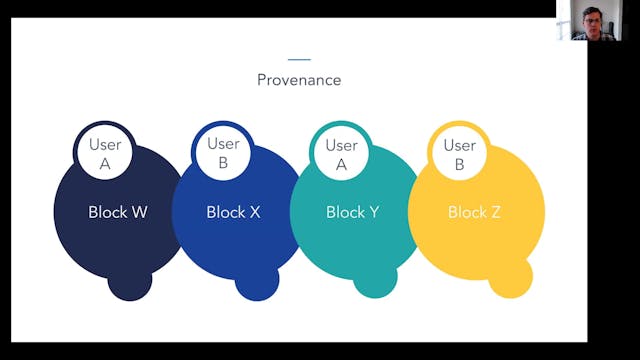
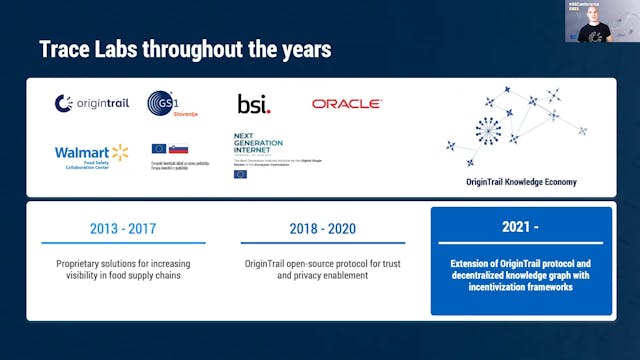
Branimir Rakic | OriginTrail: Decentralized Knowledge Graph
Knowledge graphs are powerful tools used by organizations to integrate their siloed data into useful, machine readable information for a wide range of purposes. The OriginTrail Decentralized Knowledge Graph (DKG) extends this approach to enable trusted knowledge exchange between multiple organiza...
-
Cedric Berger | Data Governance 4.0 Applied To A Unified Clinical Data Model
Driven by legacy paper-based approaches, the design, conduction and analysis of clinical studies requires the creation and transformation of many data in many different formats. This hinders the process and necessitates significant resources. Having metadata-driven transformation is not new, howe...
-
Chaitan Baru | Open Knowledge Network
The concept of an Open Knowledge Network (OKN) is one of the components of the National Science Foundation’s Harnessing the Data Revolution (HDR) Big Idea, with the objective of providing semantic information infrastructure. By encoding information and knowledge about real-world entities and thei...
-
Chen Zhang & Dmytro Dolgopolov | Entity Disambiguation With Knowledge Graph
During the presentation, we will share our experience in building a knowledge graph leveraging Spark, NLP, and Machine Learning. We will start with explaining the business problems and challenges. Then walk through our data pipeline, including text analytics processes, name similarity solutions, ...
-
Chris Welty | Shopping Sense: Bringing Common Sense To Worldwide Shopping
Knowledge Graphs (KGs) continue to penetrate the industrial world after Google's famous "things not strings" was used to explain their acquisition of FreeBase ten years ago. While many KGs exist, they are by and large little more than "entity catalogs", missing entirely the links between those e...
-
Dan McCreary | Graph Hardware Is Coming!
In this presentation we will show how current general-purpose CPU hardware fails to deliver high performance graph analytics. We show that by doing a detailed analysis of the actual hardware functionally needed by graph queries (pointer jumping), we can redesign hardware that is optimized for fas...
-
Freddy Lecue | On The Role Of Knowledge Graphs In Explainable Machine Learning
Machine Learning (ML), as one of the key drivers of Artificial Intelligence, has demonstrated disruptive results in numerous industries. However one of the most fundamental problems of applying ML, and particularly Artificial Neural Network models, in critical systems is its inability to provide ...
-
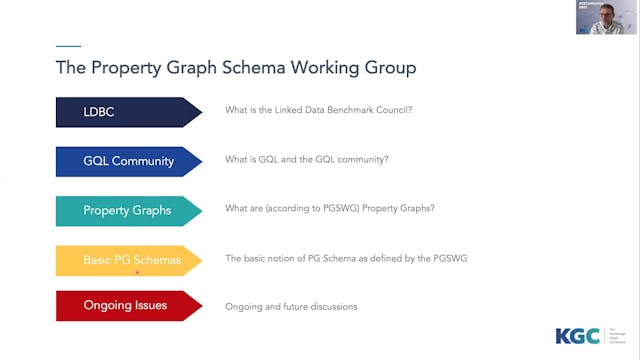
Jan Hidders | A Report From The Property Graph Schema Working Group
The Property Graph Schema Working Group (PGSWG) is an informal working group that was set up in 2018 under the umbrella of LDBC, the Linked Data Benchmark Council, to support the formal working group that works on the SQL/PGQ and GQL, the upcoming ISO/IEC standards for managing property graphs. T...
-
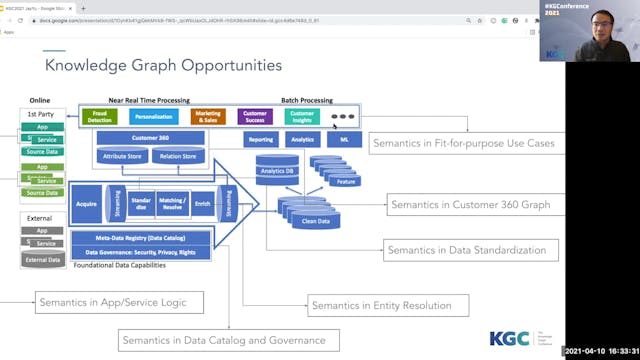
Jay Yu | Weave Knowledge Graph Tech In Enterprise Data Architecture
Intuit is embarking on a multi-year journey to transform from a financial product-centric company into an "AI-driven Expert Platform" company. We have aligned our enterprise data architecture and strategy to the company growth strategy, with a clean end-to-end enterprise architecture that embrac...
-
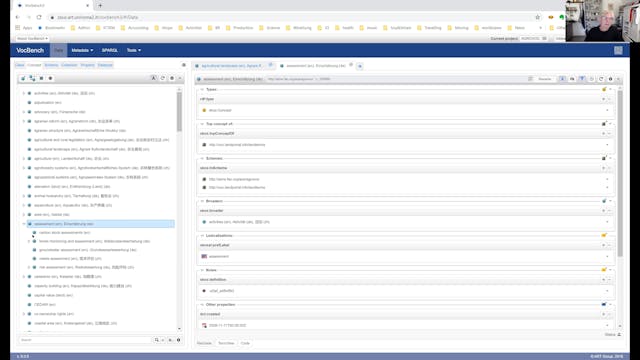
Johannes Keizer | VocBench: A Semantic Web Collab Dev. Platform For Ontologies
This presentation will feature and demonstrate "VocBench", an semantic web collaborative development platform for ontologies, thesauri and lexicons.
VocBench has initially been developed for maintenance of the thesaurus "Agrovoc". It has become then a generic tool for thesaurus management and now... -
Joshua Shinavier | Anything To Graph
Show me your schemas, and I will show you a graph! Although graph databases have become very popular in the enterprise, deep expertise in graphs is still in short supply (see "Building an Enterprise Knowledge Graph @Uber: Lessons from Reality" from KGC 2019). Developers often think of graphs as a...
-
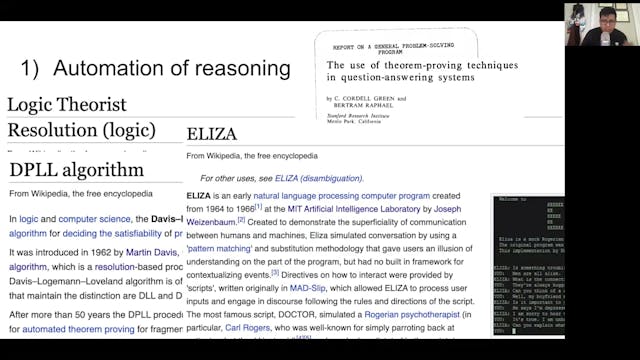
Juan Sequeda | History Of Knowledge Graphs: Main Ideas
Knowledge Graphs can be considered as fulfilling an early vision in Computer Science of creating intelligent systems that integrate knowledge and data at large scale. Stemming from scientific advancements in research areas of Semantic Web, Databases, Knowledge representation, NLP, Machine Learnin...
-
Julian Grummer | What Can We Learn From Knowledge Graphs: A Wirecard Perspective
The Wirecard scandal was one of the most shocking economic events in Germany in 2020. The former DAX30 company collapsed on June 25, owing creditors more than €3.5 billion (almost $4 billion) after disclosing a gaping hole in its books that its auditor EY said was the result of a sophisticated gl...
-
Justin Zhen & Francois Scharffe | Building Data Products Using No-code KGs
Description: The switch to decentralization in data management is finally happening as organizations struggle with a disconnect between data teams and domain knowledge. Once a new organizational structure around data domains is in place, the need for platforms for managing data products appears. ...
-
Keshav Pingali | High Performance Knowledge Graph Computing On Katana Graph
Knowledge Graphs now power many applications across diverse industries such as FinTech, Pharma and Manufacturing. Data volumes are growing at a staggering rate, and graphs with hundreds of billions edges are not uncommon. Computations on such data sets include querying, analytics, pattern mining,...
-
Konstantin Todorov | Browsing The Web Of Claims
How do falsehoods spread on the web? This and other questions related to the propagation of fake news and biased discourse in the public area have been drawing increasing interest in different communities from social sciences to artificial intelligence. Online discourse, i.e. claims and opinions ...
-
Krzysztof Janowicz | Know, Know Where, KnowWhereGraph
The KnowWhereGraph project aims at providing a densely interlinked knowledge graph for environmental intelligence applications and situational awareness services (area briefings) that enrich the data of decision-makers and data scientists with pre-integrated data custom-tailored to their spatial ...
-
Laura Ham | Introduction To Weaviate Vector Search Engine
This talk is an introduction to the vector search engine Weaviate. You will learn how storing data using vectors enables semantic search and automatic data classification. Topics like the underlying vector storage mechanism and how the pre-trained language vectorization model enables this are tou...
-
Luke Feeney | Why A Knowledge Graph Is Best For Distributed Collaboration
There has been an explosion of tools - especially in the machine learning space - describing themselves as ‘git for data’. This talk will review the main open source players and link the interest to data mesh architectures. Not to jump to outcomes without first conducting the review, but it will ...
-
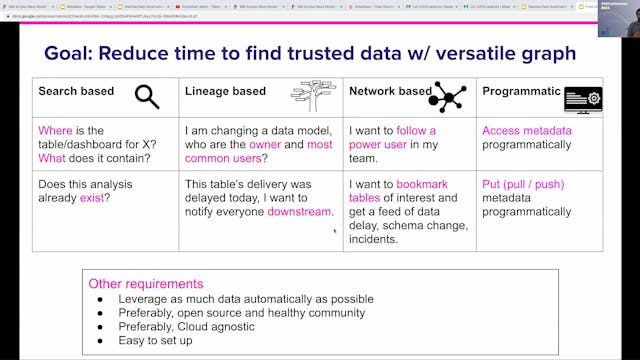
Mark Grover | From Discovering To Trusting Data
Over a third of analyst time is spent in understanding what data exists, can it be trusted and how to use it. Countless Data Engineering time is spent in answering the same questions about data - what does that column mean, how does it get populated, how often does it update and if there’s any in...
-
Ben Szekley | How To Build Enterprise Scalability Knowledge Graph Platforms
In recently naming graph technology one of their top 10 trends data and analytic trends for 2021, the Gartner Group highlighted an emerging pattern: today an ever increasing number of F1000 organizations are implementing graph technology not to address point graph use cases, but rather data integ...
-
Book Club | Semantic Web for the Working Ontologist, Chapter 5
-
Book Club | Semantic Web for the Working Ontologist, Chapters 1 - 3
-
Bookclub | Demystifying OWL for the Enterprise, Chapter 2
-
Bookclub | Demystifying OWL for the Enterprise, Chapter 1
-
Book Club | Semantic Web for the Working Ontologist, Chapter 13
-
Annotating Tabular Data using Semantic Data Dictionaries
-
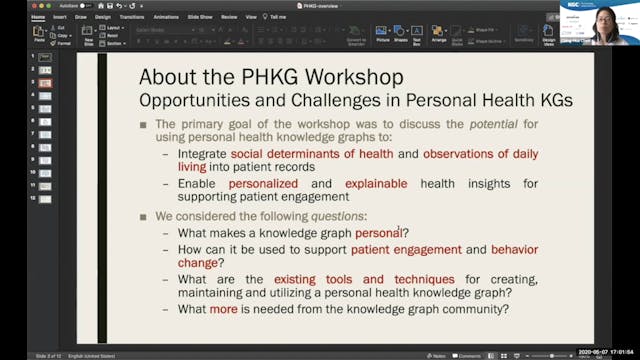
Workshop | Personal Health Knowledge Graphs, Pt 2
-
Jonas Almeida | Data Commons In The Wild - It's An API World Out There
The increasing reliance on distributed epidemiological data sources for time sensitive analysis defines an emergent computational commons space: API ecosystems supporting epidemiology data commons. This space has been forced to evolve significantly to meet the real-time requirements of COVID-19 i...
-
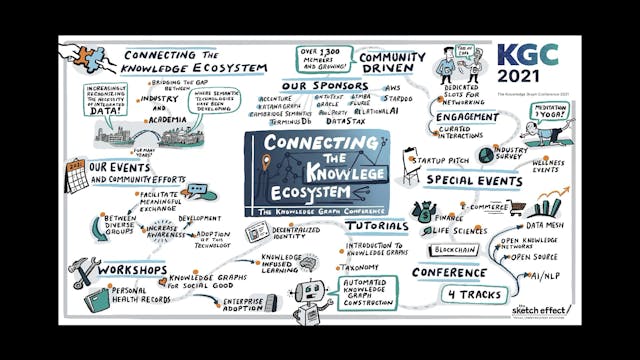
KGC 2021 Overview
-
Ora Lassila | A Knowledge Graph is More Than Just a Graph Database
Customer adoption of graph databases is growing rapidly and has attracted many vendors and products. Graphs, as an abstraction, are a simple and intuitive way to model information about the world. Despite this, the learning curve for building a graph-based application remains steep and daunting, ...
-
Nicole Moldovan | NLP: A Cornerstone for a Successful Graph
We’ll explore how unstructured and structured data can come together to tell a complete story through the lens of a pharma clinical trial and subsequent events in the field. We’ll weave through the patient history and other documents using an ontology and several NLP tools, then use natural langu...
-
Michael Grove | How To Build a Data Fabric
The enterprise data landscape is increasingly hybrid, varied, and changing. The emergence of IoT, rise in unstructured data volume, increasing relevance of external data sources, and trend towards hybrid multi-cloud environments are obstacles to satisfying each new data request. The old data stra...
-
Eelke van der Horst | Building an Immuno-Oncology & Cell Therapy Knowledge Graph
Bristol-Myers Squibb (BMS) is a global pharmaceutical company with drug discovery and development programs in several therapeutic areas. As part of its enterprise information governance, there is an ongoing effort to unlock research data from siloed systems, by building a knowledge graph that tra...
-
KGC 2021 Sponsors
-
KGC 2021: See For Yourself!
-
Graph-Based Data Science
-
How Graphs Improve Systems Thinking
-
Paths to More Personal and Collaborative Knowledge Graphs
-
Workshop | Knowledge Infused Learning
-
Foundation for a Knowledge Graph | Taxonomy Design Best Practices
-
Startup Pitch Event
-
Modeling Sustainability
-
Intro to Data Mesh
-
FAIR Data Knowledge Graphs | From Theory to Practice
-
Workshops & Tutorials Overview
-
Introduction to Knowledge Graph | Managing Big Data
Ellie Young explains what knowledge graphs are, how they solve problems with Big Data, and how to build one.
-
Enterprise Knowledge Graph Workshop
-
Workshop | Personal Health Knowledge Graphs, Part 2
Electronic health records (EHRs) have become a popular source of observational health data for learning insights that could inform the treatment of acute medical conditions. Their utility for learning insights for informing preventive care and management of chronic conditions however, has remaine...
-
From Semantic Networks to Knowledge Graphs
Since the 1960s, semantic networks of various kinds have been used for knowledge representation in AI and NLP. From the mid 1990s to 2005, Tim Berners-Lee and his colleagues adapted that technology to the Semantic Web. During the past 15 years, research in AI and related fields has created new op...
-
Demo | Ontotext GraphDB
Vassil Momtchev announces new features of GraphDB and Ontotext platform
-
Visual Analytics of Large Knowledge Graphs
Grasping large Knowledge Graphs is challenging. We present SemSpect, an innovative tool that brings together overview and detail view into one perspective by visually aggregating graph nodes and relationships for efficient exploration and data-driven querying of graphs. It comes either with a rea...
-
Personal Knowledge Graphs on the Web
In today’s data-driven economy, the company with the most data wins. This means that companies go through great lengths to collect all of our data, sometimes even crossing ethical boundaries. But in the end, we all lose: having the best data process is not an indication of how well a company inno...
-
A Data Catalog Should be Your Organization's first Knowledge Graph
In this presentation, we'll cover why a data catalog is the first knowledge graph that an organization should build. Most organizations don't have a clear picture of their data assets and how they're being used - a data datalog helps provide that picture and unlock the value of data. We'll explor...
-
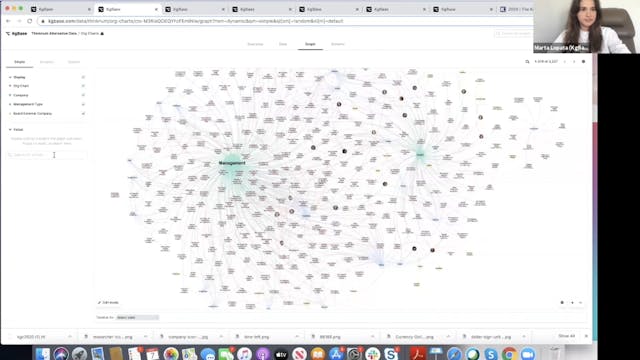
Demo | KgBase
This is a product demonstration presented by Marta Lopata from KgBase and she is here to show their knowledge graph tool. She is here to show why they created the tool and how it is used to develop their graphs itself. #knowledgegraphs #knowledgegraphconference #knowledgegraphsoftware
-
Why Semantic Objects Please App Devs with GraphQL
-
Elisa Kendall | Using FIBO: A Use-Case Driven Cooks Tour
The Financial Industry Business Ontology (FIBO) has matured in significant areas over the last few years, but until recently there were few examples to help users understand how to interpret it and build it into their own knowledge graphs. Since early 2019, the FIBO development team has been focu...
-
Q&A | John F Sowa and Vassil Momtchev
Francois Scharffe leads the Q&A between Vassil Momtchev from Ontotext and John Sowa from Kyndi.
-
Q&A | Francois Scharffe, Neda Abolhassani, Paul Groth and Ron Bekkerman
Q&A of the first session of day 1. Here our own Francois Scharffe, Neda Abolhassani from Accenture Labs, Paul Groth from the University of Amsterdam and Ron Bekkerman from Cherre answer some questions from the audience.
-
Tutorial Rapid Knowledge Graph Development with GraphQL and RDF Databases
The enterprise knowledge graphs help modern organizations to preserve the semantic context of abundant accessible information. They become the backbone of enterprise knowledge management and AI technologies with the ability to differentiate things versus strings. Still, beyond the hype of repacka...
-
Modeling Real Estate Ecosystem with Cherre's Knowledge Graph
Cherre’s knowledge graph is a model of the entire US real estate ecosystem. The graph incorporates hundreds of millions of entities such as properties, addresses, individual and commercial owners, lenders, brokers, estate managers, lawyers etc. as nodes – while the edges are various types of conn...
-
Q&A | Cyber Control Ontology and Knowledge Graphs
Q&A of Session 5 with Bethany Sehon, & Brian Donohue from Capital One, Radu Marian from Bank of America and Nicolas Seyot from Morgan Stanley.
-
Automated Knowledge Base Creation in Finance
The Information Management team (including Nicolas Seyot) at Morgan Stanley has built an RDF graph and a semantic knowledge base to help answer domain specific questions, formulate classification recommendations and deliver quality search to our internal users. In doing so over the past 4 years, ...
-
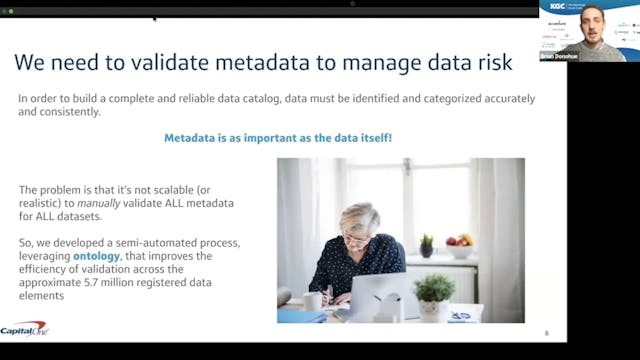
Validating Data Categories using Knowledge Graphs
One of the challenges in protecting consumer privacy and managing data risk is the ability to validate that privacy-related data from across our data ecosystem has been identified and categorized accurately and consistently. This challenge has become especially salient in light of recent legislat...
-
Inventory Management using Knowledge Graphs
Predictive analytics in inventory management has not been the traditional domain of knowledge graphs and semantics; however, it is a surprisingly natural fit. This talk will review knowledge graphs in the supply chain and look into the details of implementation. In our central case, using a seman...
-
Startup-Investor Pitch Event Winner Nayya
Akash Magoon presents Nayya, the winner of the startup-investor pitch event. Nayya is a digital health platform that integrates with a company's benefit to help employees find, book, and access high-value care.
-
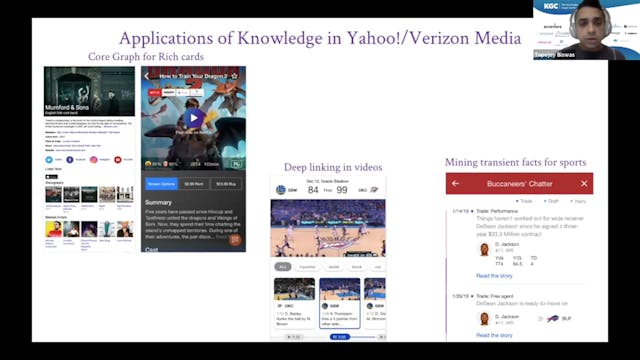
Machine Learning in Yahoo Knowledge Graph
The Yahoo Knowledge(YK) graph crawls, reconciles and blends information (around 10B fact triples) from 200 M entities across 30 semi-structured source (crawlable sites like Wikipedia, IMDB, LonelyPlanet etc and as well licensed feeds) graphs to a merged graph of 75 M entities, 5B facts distribute...
-
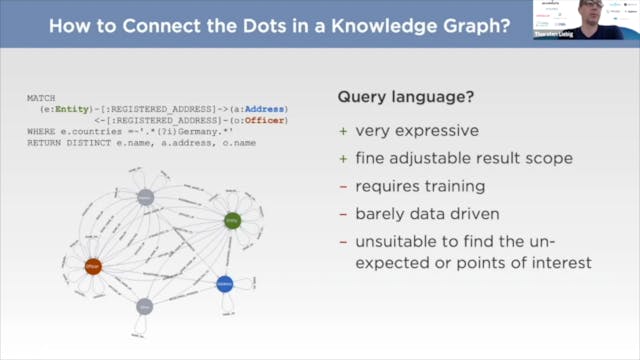
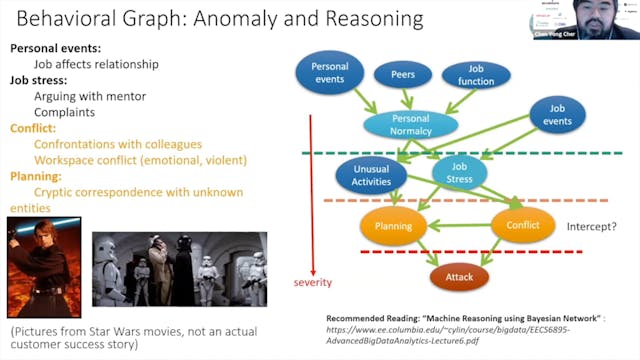
Q&A | Thorsten Liebig, Gavin Mendel-Gleason, and Chen Yong Cher
Q&A with Thorsten Liebig from Derivo, Gavin Mendel-Gleason from TeminusDB, and Chen Yong Cher from Graphen
-
Workshop | Knowledge Graphs for Social Good
The United Nations (UN) supports 17 Sustainable Development Goals (SDGs) covering topics from poverty to healthcare, education, and beyond. This workshop will gather a community from which to discuss ongoing industry work, academic research efforts, and include a collaborative ideation exercise. ...
-
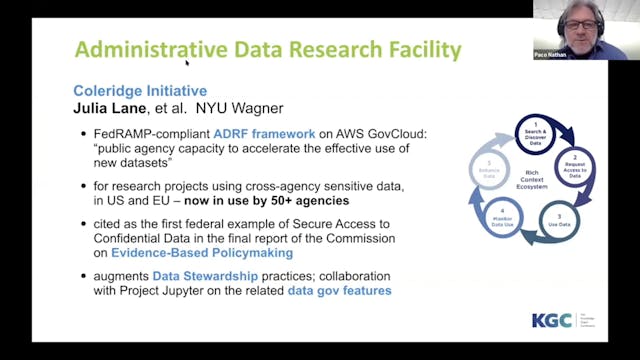
Rich Context | A Knowledge Graph for Linking Datasets with Research Outcomes
The Rich Context project at NYU Wagner is the knowledge graph complement to the ADRF platform for cross-agency social science research using sensitive data, currently used by 50+ agencies. Rich Context represents metadata about datasets and their use in research which in turn influences public po...
-
Using Graph Analytics in Enterprise Applications
Graphs provide a new dimension to managing and analyzing data, and enterprises are keen to explore and adopt this technology. There have been some barriers to adoption, including a lack of familiarity with graph query languages and tools and challenges in integrating graph analytics into existing...
-
Q&A | Silviu Cucerzan, Konstantin Todorov, and Dylan Roy
Q&A of the 4th session with Silviu Cucerzan of Microsoft Research, Konstantin Todorov of the University of Montpellier, and Dylan Roy from Dow Jones.
-
Entity Linking | The Symbiosis between Knowledge Graphs and News
The development and availability of Web knowledge repositories, in particular Wikipedia, as the largest general-knowledge encyclopedic collection, have changed remarkably not only the way in which individual users fulfill their informational needs but also the way in which information providers o...
-
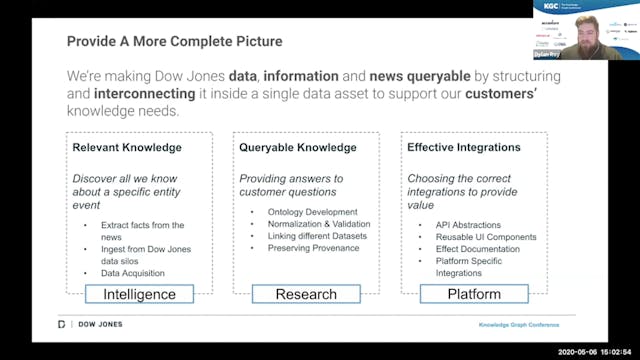
Better Informing our Readers through the Dow Jones Knowledge Graph
In today’s world understanding the full context of an event is not an easy thing, especially in a world where there’s countless sources of low quality one dimensional content is fighting for our attention. Which leaves most readers of the news uniformed or spending time piecing together incomplet...
-
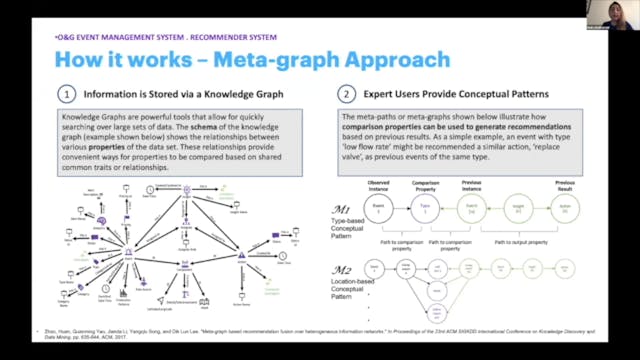
A Meta-Graph Solution for Recommender Systems
The proposed meta-graph solution for recommender systems is a living process for semi-automatically resolving recommendations using guided queries upon a knowledge graph. In addition, this solution is explainable; it can provide comprehensible recommendations which show the reason for each result...
-
Introduction to the Knowledge Graph Conference 2020
KGC organizer François Scharffe opening address
-
Boost Your Graph with Semantic NLP
Boost your Graph with Semantic NLP: Nicole Moldovan from Lymba talks about the Lymba platform and how Knowledge Graphs help produce better results in this demo called Boost your Graph with Semantic NLP. Nicole shows the viewers a problem some customers face with unstructured data. Afterwards, Nic...
-
A Knowledge Graph of Controversial Claims and its Applications
Expressing opinions and interacting with others on the Web has led to the production of an abundance of online discourse data, such as claims and viewpoints on controversial topics, their sources and contexts (e.g., events, entities). These data constitute a valuable source of insights for studie...
-
Workshop Personal Health Knowledge Graphs | Part 1
Electronic health records (EHRs) have become a popular source of observational health data for learning insights that could inform the treatment of acute medical conditions. Their utility for learning insights for informing preventive care and management of chronic conditions however, has remaine...
-
Chen Yong Cher | Enterprise Knowledge Graph and Machine Learning Integration
In the realm of enterprise applications such as cybersecurity and anti-money laundering (AML), data and system engineers team up to deal with interconnected data of great scale and richness. The regulatory need adds requirements to instant tracibility and explanability of data and analytic models...
-
Knowledge Graph Maintenance
Knowledge graphs are increasingly built using complex multifaceted machine learning based systems relying on a wide of different data sources. To be effective these must constantly evolve and thus be maintained. I present work on combining knowledge graph construction (e.g. information extraction...
-
Book Club | Semantic Web for the Working Ontologist, Chapter 6
-
Book Club | Demystifying OWL for the Enterprise, Chapter 3
-
Book Club | Demystifying OWL for the Enterprise with Michael Uschold, Chapter 8
-
Book Club | Semantic Web for the Working Ontologist, Chapter 12
-
Book Club | Demystifying OWL for the Enterprise, Chapter 5
-
Book Club | Semantic Web for the Working Ontologist, Chapter 7
-
Book Club | Semantic Web for the Working Ontologist, Chapter 14
-
Book Club | Demystifying OWL for the Enterprise with Michael Uschold, Chapter 6
-
Book Club | Demystifying OWL for the Enterprise with Michael Uschold, Chapter 7
-
Book Club | Semantic Web for the Working Ontologist, Chapter 11
-
Book Club | Semantic Web for the Working Ontologist, Chapter 4
-
Book Club | Semantic Web for the Working Ontologist - Chapter 10
Ellie Young, Dean Allemang and James Hendler discuss and answer questions regarding first chapters of 'Semantic Web for the Working Ontologist'.
-
Book Club | Demystifying OWL for the Enterprise, Chapter 4
-
Book Club | Semantic Web for the Working Ontologist, Chapter 8
-
Book Club | Semantic Web for the Working Ontologist, Meet & Greet
Ellie Young, Dean Allemang and James Hendler discuss and answer questions regarding first chapters of 'Semantic Web for the Working Ontologist'.
-
Knowledge Espresso | Paco Nathan
Listen to Paco Nathan answering questions in the field of knowledge graphs, ontology and machine learning.
-
Knowledge Espresso | Atanas Kiryakov on Applications of Knowledge Graphs
-
Knowledge Espresso | Dan McCreary on Graph Embeddings
-
Knowledge Espresso | Luke Feeney: Introduction to TerminusDB
-
Knowledge Espresso | Jon Herke and Futurist Academy Students
-
Knowledge Espresso | Introduction to Grakn with Daniel Crowe and Tomas Sabat
-
Knowledge Espresso | Michael Bronstein and Francois Scharffe
-
Knowledge Espresso | Knowledge Connexions Preview
-
Knowledge Espresso | "So You Want to Deploy Your First Knowledge Graph?"
-
Knowledge Espresso | Why Data-Centricity Matters with Brian Platz from Fluree
-
Knowledge Espresso | Ruben Verborgh on the Solid Ecosystem
-
Knowledge Espresso | Q&A with Panos Alexopoulos
-
Knowledge Espresso | Francois Scharffe and W3C
-
Knowledge Espresso | Aaron Bradley from Electronic Arts
-
Knowledge Espresso | Branimir Rakic from OriginTrail
-
Knowledge Espresso | Mike Grove from StarDog
Listen to Mike Grove talk about job opportunities at Stardog, the difference between Stardog and other vendors in the market, and how to sell knowledge graphs to enterprise.
-
Knowledge Espresso | Sebastian Hellmann on DBPedia: The Backbone of Linked Data
-
Knowledge Espresso | Technical approaches to graphing communities
Brendan Newlon talks about the usage of knowledge graphs to determine relationships between communities. He walks through his dissertation and approaches used to differentiate Muslim communities. The same technique is used with Jewish communities and clearly shows that there are differences betwe...
-
Knowledge Espresso | Alan Morrison: Four Emerging KG Use Cases + Insights
-
Knowledge Espresso | Clare Hooper
Listen to Clare Hooper and Ellie Young discuss the usage of knowledge graphs for personalized and tailored website experience.
-
Want Agile Data Management?
Knowledge graphs are a powerful tool for integrating and making sense of data - but the current state of most organizations is addressing more basic issues of data cataloging and governance. We'll discuss how our customers Deloitte, Mirum, and the Associated Press are using graphs (often without ...
-
Office Hours | Dean Allemang and Michael Uschold
-
Office Hours | Mike Grove from Stardog, October 13
-
Office Hours | Paco Nathan, Dec18
-
Office Hours | Paco Nathan, October 23
-
Office Hours | Michael Uschold from Semantic Arts
-
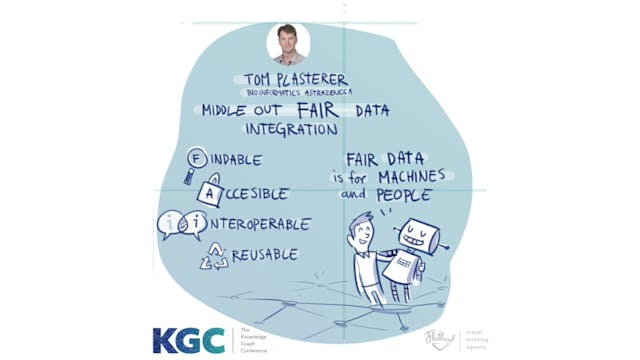
Middle-Out FAIR Data Integration with Knowledge Graphs
An extremely powerful and efficient use for Knowledge Graphs is to unite well-understood domains of knowledge alongside novel and specific business/scientific questions. Using small ontologies that embed large reference taxonomies, we are able to go from tactical scientific questions (bottom-up) ...
-
Office Hours | Paco Nathan, Nov 19
-
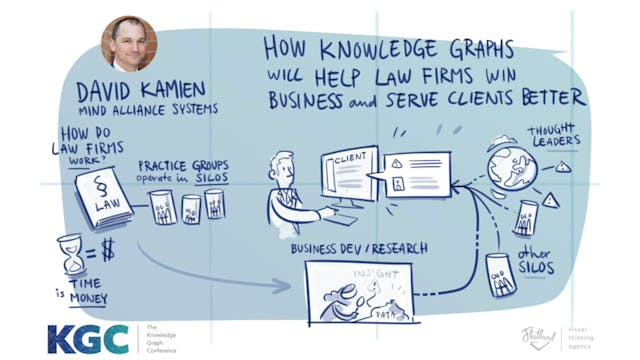
How Knowledge Graphs can help Law Firms win Business and Serve Clients Better
Law firms are starting to build knowledge graphs to power next-generation marketing and business development applications that efficiently integrate data and help deliver the most important intelligence insights to the right people sooner. These systems help firms spot opportunities sooner, autho...
-
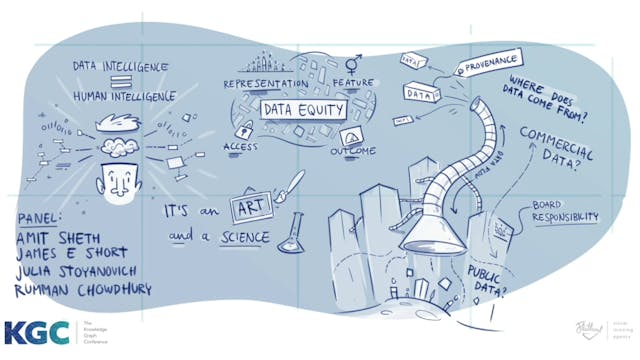
Panel | Frontiers in Data Intelligence
Panel: Frontiers in Data Intelligence. What is data intelligence? Who owns knowledge graphs? How do we define contexts of use for knowledge graphs? How to make sure knowledge graphs offer equitable utility?
-
Q&A | John F Sowa and Vassil Momtchev
Francois Scharffe leads the Q&A between Vassil Momtchev from Ontotext and John Sowa from Kyndi.
-
From Card Sorting to Data Automation: PoolParty—A Complete Semantic Middleware
Andreas Blumauer is CEO of Semantic Web Company and he is here to show how to use semantics to drive the business value of your data using the PoolParty Semantic Suite. Andreas has a mission to free customers from data silos and enrich the data with semantic metadata and he believes the software ...
-
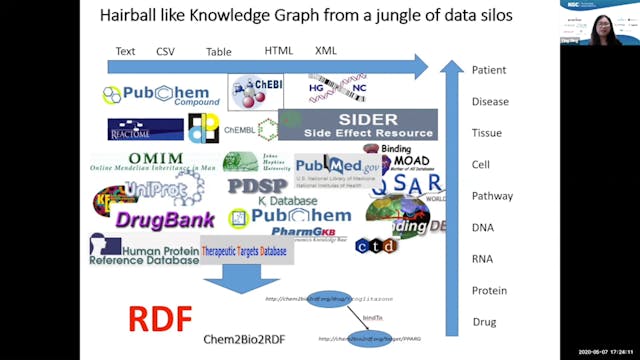
Mining Knowledge Graph for Drug Discovery
2020 Talk: Knowledge Graph for Drug Discovery: A critical barrier in current drug discovery is the inability to utilize public datasets in an integrated fashion to fully understand the actions of drugs and chemical compounds on biological systems. There is a need to intelligently integrate hetero...
-
Q&A | Huda Khan, David Kamien and Rafael Goncalves
Q&A with Huda Khan from Cornell University, David Kamien from Mind Alliances System and Rafael Goncalves from Stanford University.
-
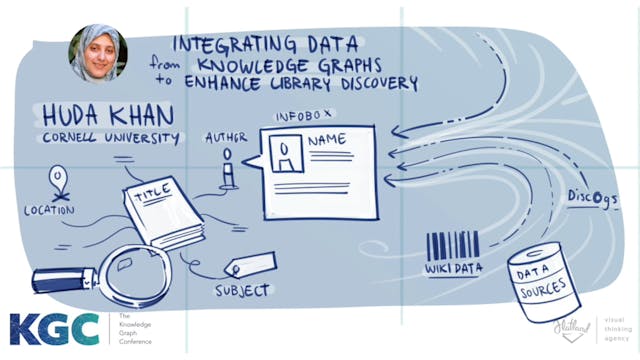
Integrating data from knowledge graphs to enhance library discovery
As part of the Linked Data For Production: Pathway to Implementation (LD4P2) project’s larger goal of building a pathway to the use of linked data in the description of library resources, we are exploring the integration of linked data sources in library discovery interfaces. Through a series of ...
-
Workshop Summary | The Personal Health Knowledge Graph
Ching-Hua Chen summarizes and talks about the workshop on Personal Health Knowledge Graph.
-
Q&A | Jans Aasman, Mike Grove, and Dr. Ora Lassila
Juan Sequeda from data.world moderates this Q&A with Jans Aasman from Allegro Graph, Mike Grove from Stardog and Dr. Ora Lassila from AWS.
-
Are Knowledge Graphs a Good Thing?
Yes. Why? Because building a knowledge graph means you are consolidating your important knowledge assets, and that forces you to think of the “bigger picture” of all the data you have in your organization including shared, common domain models. You are not merely shoving data into a warehouse, bu...
-
Insufficient Facts Always Invite Danger: Combat them with a Logical Model
Insufficient Facts Always Invite Danger: Combat Them with a Logical Model While understanding the context of data is key, it's important to remember there is no universal context. What makes sense in one case may not in another. We see this often in MDM scenarios; we can't agree on the definition...
-
The Curious Case of the Semantic Data Catalog
The Curious Case of the Semantic Data Catalog: Knowledge graphs have been on the rise and organizations have found a variety of use cases for the technology. One specific type of use case is the implementation of a knowledge graph as a semantic data catalog. With the inherent power of the technol...
-
The Knowledge Graph that Listens
Enterprises that are building Knowledge Graphs are rapidly getting a grip on unstructured data with current advances in Natural Language Processing (NLP) techniques. But there is still a large mass of unstructured data that is untapped and that is spoken conversations with customers. Speech to te...
-
Preview Elisa Kendall
-
Tutorial Introduction to Logic Knowledge Graphs
A hands-on tutorial that will introduce logic knowledge graphs via TerminusDB to those beginning or looking to develop their knowledge graph journey.
-
Rich Context | A Knowledge Graph for Linking Datasets with Research Outcomes
The Rich Context project at NYU Wagner is the knowledge graph complement to the ADRF platform for cross-agency social science research using sensitive data, currently used by 50+ agencies. Rich Context represents metadata about datasets and their use in research which in turn influences public po...
-
Panel | Frontiers in Data Intelligence
Panel: Frontiers in Data Intelligence. What is data intelligence? Who owns knowledge graphs? How do we define contexts of use for knowledge graphs? How to make sure knowledge graphs offer equitable utility?
-
Workshop summary | Knowledge Graph for Social Good
Lambert Hogenhout offers a summary of the workshop Knowledge Graph for Social Good
-
Q&A | Jans Aasman, Mike Grove, and Dr. Ora Lassila
Juan Sequeda from data.world moderates this Q&A with Jans Aasman from Allegro Graph, Mike Grove from Stardog and Dr. Ora Lassila from AWS.
-
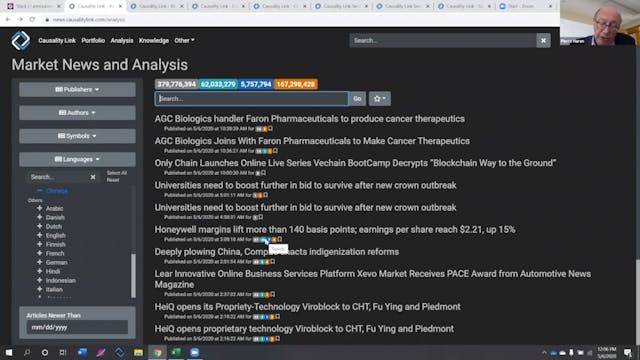
Demo Causality Link
Leveraging a graph of causal forces acting on financial markets
-
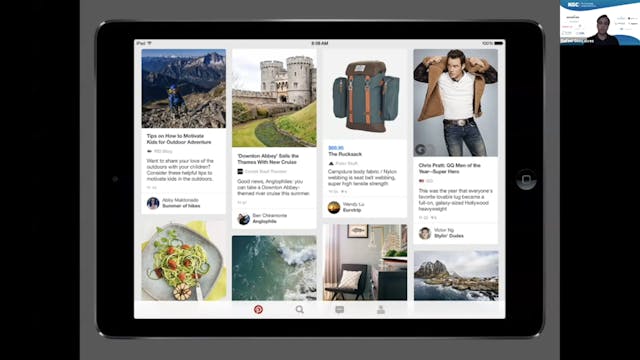
Use of OWL and Semantic Web Technologies at Pinterest
Pinterest is a popular Web application that has over 250 million active users. It is a visual discovery engine for finding ideas for recipes, fashion, weddings, home decoration, and much more. In the last year, the company decided to create a knowledge graph that aims to represent the vast amount...
-
Q&A | Ruben Verborgh, Byron Jacob, and Yanko Ivanov
Q&A with Ruben Verborgh from Ghent University, Byron Jacob from data.world and Yanko Ivanov from Enterprise Knowledge
-
Designing and Building Knowledge Graphs from Relational Databases
Knowledge Graphs are fulfilling the vision of creating intelligent systems that integrate knowledge and data at large scale. We observe the adoption of Knowledge Graphs by the Googles of the world. However, not everybody is a Google. Enterprises still struggle to understand their relational datab...
-
Book Club | Semantic Web for the Working Ontologist, Chapter 9
-
An Overview of Knowledge Graphs with Francois Scharffe
Francois Scharffe is the CEO of Knowledge Graph Conference also known as KGC. He introduces knowledge graphs and general idea of the concepts that come with the space. Francois talks about producing knowledge graphs and the use cases of knowledge graphs giving the viewers a general overview of wh...
-
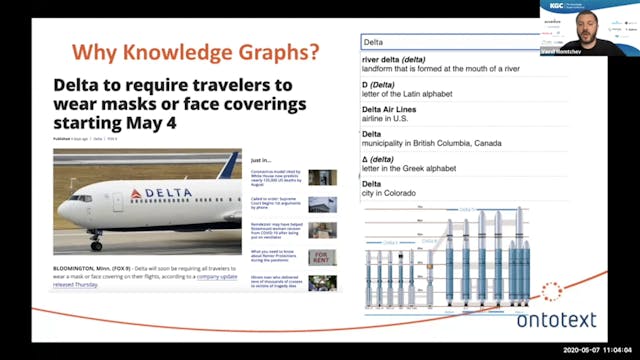
Why Knowledge Graphs
-
Panel Discussion | NLP for Knowledge Graphs
-
Panel Discussion on Life Sciences
-
Panel Discussion | Standardization Efforts For Knowledge Graphs
-
Panel Discussion | Graph Data Science
-
Knowledge Graphs for Social Good
-
Validating Semantic Knowledge graphs using SHACL
-
An introduction to Knowledge Graphs
-
Semantic Modeling for Knowledge Graphs
-
Integrating Data through Virtual Knowledge Graphs with Ontop
-
DBpedia Knowledge Graph Tech Tutorial
-
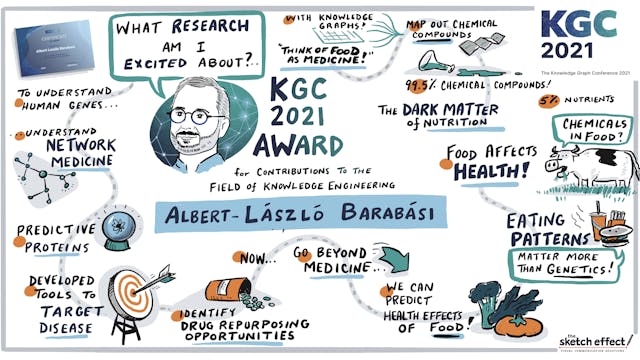
Laszlo Barabasi Award Timelapse
-
Industry Benchmark Survey Timelapse
-
KGC 2021 Award Winner | Albert-Laszlo Barabasi
-
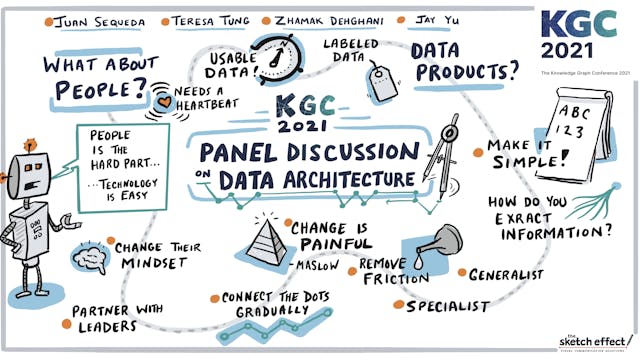
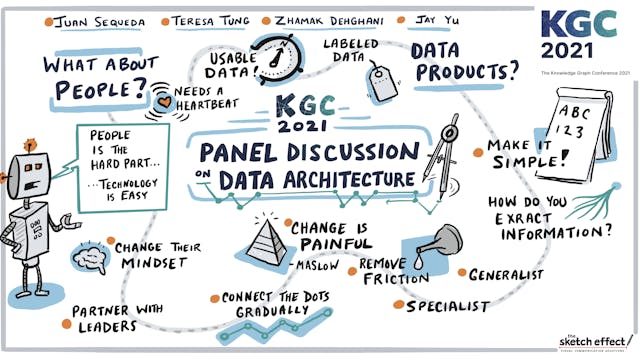
Panel Discussion | Data Architecture, Timelapse
-
Matt Gee | Known Unknowns: Promoting Collaborative Data Ecosystems with KGs
Despite the estimated 70 zettabytes of data produced worldwide, the production and use of data is unequal and its conversion to knowledge uneven across communities and sectors. To address this data & knowledge inequality, both the public and philanthropic sectors are increasing investments in...
-
Panel Discussion | OKN
-
Panel Discussion | Search
-
From Network Medicine to Food and Knowledge Graphs
Albert Laszlo Barabasi is here to to talk about what he is most excited which is network medicine. Albert presents what network medicine is, which is a network-based approach to human diseases and he explains that the existence of disease module is important because it would benefit if you reall...
-
From Vision to Reality | A Fireside Chat with Knowledge Graph Trailblazers
In this panel discussion leaders from Raytheon, Bosch, Merck KGaA, and Deloitte will share their vision for knowledge graph technology and describe how they are translating that vision into reality within their own Digital Twin, Regulatory Data Fabric, and Operational Resilience initiatives. Wit...
-
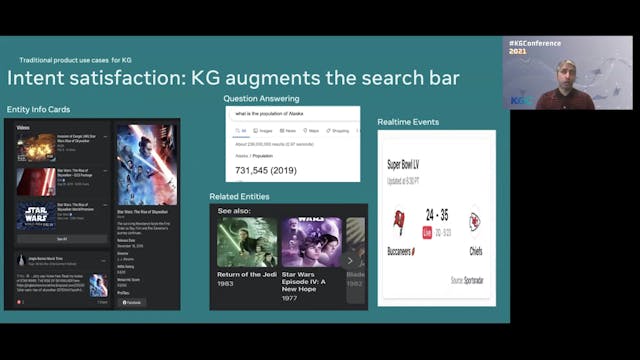
Duane Forrester | Your Future in Search is Built on Knowledge Graphs
The future of search is already known, and it's built on Knowledge Graphs. From a business' POV, we'll explore the focus of search engines today, why KGs are so integral and examine the benefits of building your own site around a knowledge graph. From increases in customer retention, conversion a...
-
Panel Discussion | Data Architecture
-
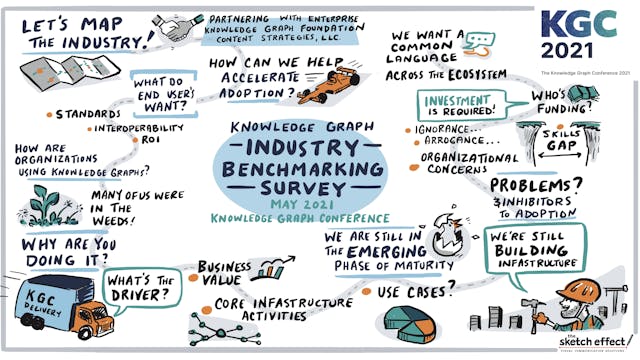
Knowledge Graph Industry Survey
-
Knowledge Espresso | Nicole Moldovan from Lymba on Enterprise Knowledge Graph
-
Knowledge Espresso | Heather Hedden: Taxonomy Trends
-
Introduction to Data Mesh | A paradigm shift in managing analytical data
-
Knowledge Espresso with Mike Atkin | The Future of Data Management
-
Bookclub | Ontology Engineering: Deborah McGuiness and Elisa Kendall, Chapter 2
-
Bookclub | Ontology Engineering w Deborah McGuinness & Elisa Kendall, Chapter 4
-
Knowledge Espresso with Mike Atkin | Narrative for Positioning KGs to Execs
-
Knowledge Espresso with Molham Aref: Relational is the Future of Graphs
-
Knowledge Espresso with Ora Lassila and Juan Sequeda
-
Knowledge Espresso | Metaphacts wth Kai Preuss + Sebastian Schmidt
How to achieve buy-in for your knowledge graph projects, while empowering your organization to drive KG democratization
Over the course of building 50+ semantic KG-based apps with clients, metaphacts has developed a systematic approach based on the metaphactory platform for empowering domain exp...
-
The Knowledge Graph Cookbook | The Method of Its Construction
In Session 1 of The Knowledge Graph Cookbook, Andreas Blumauer and Helmut Nagy introduce The Method of Its Construction and provide an overview of the book.