Machine Learning in Yahoo Knowledge Graph
KGC | The Complete Collection
•
22m
The Yahoo Knowledge(YK) graph crawls, reconciles and blends information (around 10B fact triples) from 200 M entities across 30 semi-structured source (crawlable sites like Wikipedia, IMDB, LonelyPlanet etc and as well licensed feeds) graphs to a merged graph of 75 M entities, 5B facts distributed across 140 entity types and 300 attributes. From classifying entity type of source entities, to reconcile entities across sources (e.g. Brad Pitt from Wikipedia vs. Brad Pitt from IMDB), and blending conflicting and complementing facts for each entity from different sources, the YK graph encapsulates production scale machine learning solutions for multi-label classification(e.g. predicted entity types for Arnold Schwarzenegger could be Actor, Politician, BusinessPerson etc ), large scale high precision binary classifiers along with an array of distributed hashing techniques help scale a potential billion edge comparisons (de-duplication of entities across sources require high precision classifiers for which we develop active learning and precision clamped training strategies) and lastly hubs and authorities based fact blending from competing sources. To support product initiatives like surfacing knowledge augmented results on web and sponsored searches we build a variety of "knowledge discovery" services like 1. knowledge triples based question answering and reading comprehension type question answering utilizing our blended/merged knowledge graph, 2. related entities for a given entity to other connected entities beyond direct ontological relations to generate browsing interest to other sites/properties in Yahoo. In contrast to broad cross domain knowledge, we delve into deep domain specific information extraction from news text and videos to power unique experiences for brands like Yahoo! Sports. Specifically for US Sports (NBA/NFL/NHL/MLB/Soccer) our text information extraction sits in the cross roads of fact finding in articles, fine grained entity typing and topical extractive summarization of temporal topics like trades/contracts/injuries and performances connecting player and potential teams to provide 360 degree browsing of daily fantasy news/sports rumors. Through our Video deep linking capabilities we link moments in highlight videos to points in time of a game such that we can power within-video search/browse experiences for e.g. queries like "Lebron Jame's dunks from yesterday" would seek to exact moments in a highlight video where LeBron dunked or "Laker's top scorer's tonight" would find the stats of the top Laker's scorers, followed by seeking to exact moments of their plays in highlight videos.
Up Next in KGC | The Complete Collection
-
Q&A | Thorsten Liebig, Gavin Mendel-G...
Q&A with Thorsten Liebig from Derivo, Gavin Mendel-Gleason from TeminusDB, and Chen Yong Cher from Graphen
-
Workshop | Knowledge Graphs for Socia...
The United Nations (UN) supports 17 Sustainable Development Goals (SDGs) covering topics from poverty to healthcare, education, and beyond. This workshop will gather a community from which to discuss ongoing industry work, academic research efforts, and include a collaborative ideation exercise. ...
-
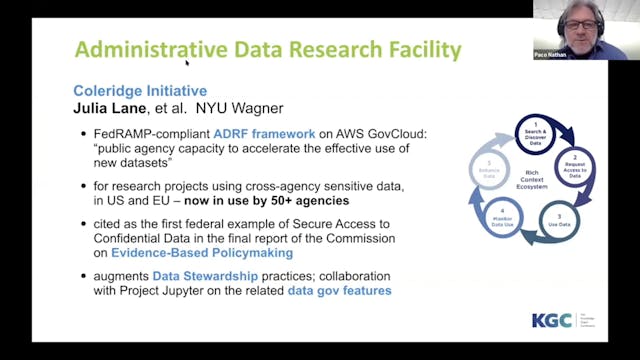
Rich Context | A Knowledge Graph for ...
The Rich Context project at NYU Wagner is the knowledge graph complement to the ADRF platform for cross-agency social science research using sensitive data, currently used by 50+ agencies. Rich Context represents metadata about datasets and their use in research which in turn influences public po...