Paolo Manghi | The OpenAIRE Research Graph: Science As A Public Good
KGC 2021 Conference, Workshops and Tutorials
•
18m
The presentation will introduce the motivations, architecture, and operation of the OpenAIRE Research Graph (http://graph.openaire.eu), one of the largest (if not the largest) public, open access, collections of metadata and semantic links (~1Bi) between research-related entities: articles (124M+), datasets (14Mi+), software (200K+), and other research products (8Mi+) and entities like organizations, funders (~25), funding streams, projects (3.5Mi+), research communities (7), and data sources (14K+). The Graph delivers to researchers, funders, communities, publishers, citizens, and SMEs/enterprises an up-to-date, global map of science across countries and disciplines, which is open and transparent, to be used to boost science and innovation. Its metadata and links are either collected (“harvested”) from 14K+ data sources (e.g., institutional/data/software repositories, publishers, registries) or inferred via full-text mining an ever-increasing collection of articles, counting today 14Mi+ objects. Conceived as a public and transparent good, populated out of data sources trusted by scientists, the OpenAIRE Research Graph aims at bringing discovery, monitoring, and assessment of science back in the hands of the scientific community and society at large. The Graph can be freely accessed via the OpenAIRE EXPLORE portal (http://explore.openaire.eu) and CONNECT portals for communities (http://connect.openaire.eu), via the PROVIDE APIs (http://provide.openaire.eu), or via data dumps made available via a dedicated community in Zenodo.org (https://zenodo.org/communities/openaire-research-graph). Its APIs count today 2Bi accesses per year, via OpenAIRE portals and as third-party services requests. Scopus, ScieVal, AMC, Springer Nature, the EC Participant Portal rely today on the service, as well as researchers and other companies and scholarly services worldwide, such as institutional repositories, aggregators, etc.
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
Paco Nathan | Graph Based Data Science
Python offers excellent libraries for working with graphs: semantic technologies, graph queries, interactive visualizations, graph algorithms, probabilistic graph inference, as well as embedding and other integrations with deep learning. However, most of these approaches share little common groun...
-
Olaf Hartig | RDF Star: Metadata For ...
The lack of a convenient way to capture annotations and statements about individual RDF triples has been a long standing issue for RDF. Such annotations are a native feature in other contemporary graph data models (e.g., edge properties in the Property Graph model). In recent years, the RDF* app...
-
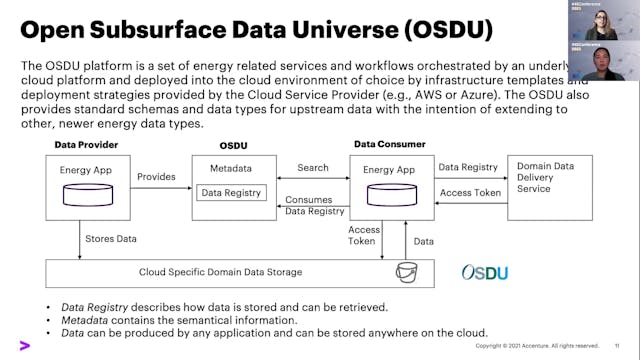
Neda Abolhassani & Teresa Tung | Acce...
A data supply chain is industry-specific, but many data prep tools are industry agnostic. As part doing this work, data engineers and domain experts apply their deep knowledge of how to transform raw data to a form that can address specific problems. In this way, the data supply chain is a doma...