Paco Nathan | Graph Based Data Science
KGC 2021 Conference, Workshops and Tutorials
•
17m
Python offers excellent libraries for working with graphs: semantic technologies, graph queries, interactive visualizations, graph algorithms, probabilistic graph inference, as well as embedding and other integrations with deep learning. However, most of these approaches share little common ground, nor do many of them integrate effectively with popular data science tools (pandas, scikit-learn, spaCy, PyTorch), nor efficiently with popular data engineering infrastructure such as Spark, RAPIDS, Ray, Parquet, fsspect, etc. This talk reviews `kglab` https://github.com/DerwenAI/kglab – an open source project that integrates most all of the above, and moreover provides ways to leverage disparate techniques in ways that complement each other, to produce Hybrid AI solutions for industry use cases.
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
Olaf Hartig | RDF Star: Metadata For ...
The lack of a convenient way to capture annotations and statements about individual RDF triples has been a long standing issue for RDF. Such annotations are a native feature in other contemporary graph data models (e.g., edge properties in the Property Graph model). In recent years, the RDF* app...
-
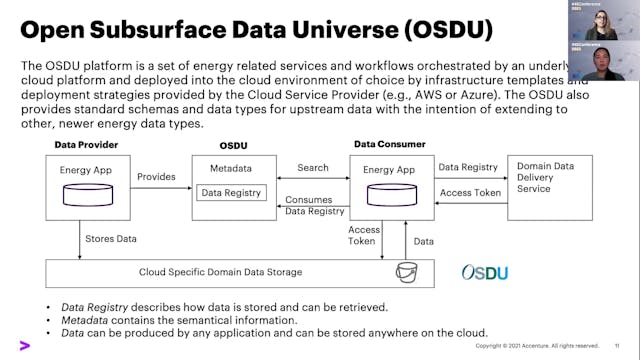
Neda Abolhassani & Teresa Tung | Acce...
A data supply chain is industry-specific, but many data prep tools are industry agnostic. As part doing this work, data engineers and domain experts apply their deep knowledge of how to transform raw data to a form that can address specific problems. In this way, the data supply chain is a doma...
-
Mohammed Aaser | Future Of Enterprise...
Many organizations have initiated data and analytics transformations with some success, however are beginning to face challenges in scaling efforts beyond a handful of applications/use cases. One of the major barriers remains around data management, including challenges with data transparency, i...