Alex Kalinowski | Structured To Unstructured & Back: Integrated KG and NLP
KGC 2021 Conference, Workshops and Tutorials
•
21m
Identification of entities and the relations between them is a difficult task for traditional pattern-based matching or machine learning approaches; these techniques rapidly overfit training datasets and struggle to transfer to other contexts or domains. Utilizing outside knowledge, such as facts contained in a knowledge base or ontology, seems to be a solution to the lack of transferability. However, integrating unstructured text data and language models with highly structured resources such as knowledge bases is a challenging research problem. Using concepts from distant supervision, word vectors and knowledge graph embeddings, an elegant unsupervised learning approach will be presented for solving this knowledge integration problem. This talk is to view the problem from both points-of-view: the natural language processing practitioner unaccustomed to semantics and knowledge bases, and the semantic web developer without a background in deep learning and language models.
Revised Description:
It is a difficult task for traditional pattern-based matching or machine learning approaches to identify entities and the relationships they share. These techniques rapidly overfit training datasets and struggle to transfer to other contexts or domains. One solution to the lack of transferability includes the utilization of outside knowledge, such as facts contained in a knowledge base or ontology. However, integrating unstructured data such as language models with highly structured data such as knowledge bases is a challenging research problem.
Using concepts from distant supervision, word vectors, and knowledge graph embeddings, an elegant unsupervised learning approach will be presented for solving this knowledge integration problem. This talk illustrates the problem from two points-of-view: the natural language processing practitioner unaccustomed to semantics and knowledge bases, and the semantic web developer without a background in deep learning and language models.
Alexander Kalinoski works on tasks as a knowledge graph engineer at Wells Fargo Bank. This video provides his insight on where users are to identify elements in a collection of unstructured data and tackling it in one way or another may leave a lot to be desired, but Kalinoski believes they can tackle it from different directions simultaneously. Kalinoski provides use cases where his solution can lead to the verification of ontology, decrease in cost and time and help identify gaps in graphs.
#knowledgegraphs #knowledgegraphconference #knowledgegraphschema #knowledgegraphandbigdataprocessing
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
Alena Vasilevich | Benefits Of Collab...
In the realm of data-driven businesses, structured data, being highly organized and easily understood by machines, is a valuable resource. IATE, with almost one million concepts storing multilingual terms and metadata, holds a large part of the textual knowledge of the EU. However, it can only be...
-
Abhishek Mittal | Re-Imagining Regula...
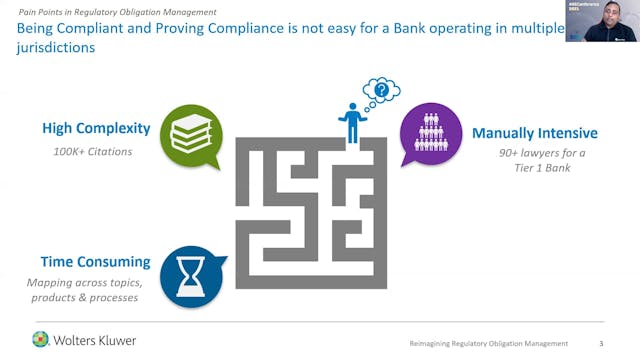
Content Enrichment: Development and deployment of a 5-stage taxonomy. Applying the taxonomy to tag regulations and classify them for improved discovery & work assignment.
Smart Authoring: Leveraging advanced NLP and ML techniques to learn from the past content authoring for identification of ... -
Zhamak Dehghani | Introduction To Dat...
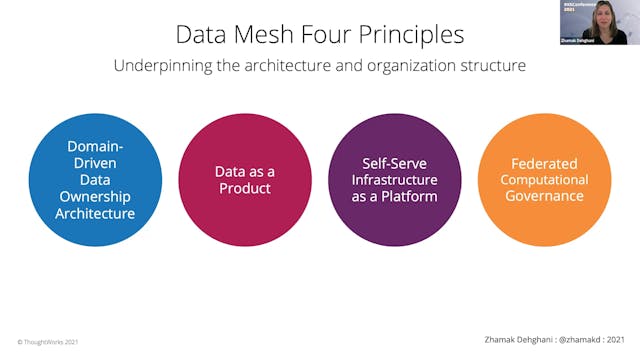
For over half a century organizations have assumed that data is an asset to collect more of, and data must be centralized to be useful. These assumptions have led to centralized and monolithic architectures such as data warehousing and data lake, and neither of which have been able to enable data...