Alena Vasilevich | Benefits Of Collaborative AI vs. Manual Creation
KGC 2021 Conference, Workshops and Tutorials
•
18m
In the realm of data-driven businesses, structured data, being highly organized and easily understood by machines, is a valuable resource. IATE, with almost one million concepts storing multilingual terms and metadata, holds a large part of the textual knowledge of the EU. However, it can only be accessed lexically, and the database concepts stand alone. If IATE were taxonomized, i.e. related concepts linked up into knowledge graphs yielding a full-fledged ontology, its data could not only be consumed by linguists but would also become accessible by the machine readable SPARQL endpoint, which makes it a powerful resource for AI projects, particularly within SMEs that rarely have the means to create multilingual formalized knowledge.
Coreon team elevated a sub-domain of IATE terminology into a multilingual knowledge graph. We taxonomized a flat list of 425 concepts within the COVID sub-domain, benchmarking two approaches to tackle this task: automatically through a custom-enhanced off-the-shelf language model and a manual creation of the knowledge graph by a linguist expert. The automatically created knowledge graph was later revised by a human, corrections and time effort measured and compared with performance metrics of the manual approach. In this talk, we will dwell on performance and resource-saving advantages of our custom method and show how the achieved productivity rate can make the taxonomization of even large terminology databases economically viable.
We demonstrate empirically the effectiveness of our collaborative-robot approach in a typical industry use case scenario: using the resulting IATE/Covid graph for initialization of a Convolutional Neural Network (CNN) in a multilingual document classification task, we get a classification granularity that is not reachable by state-of-the-art models, such as non-initialised CNNs and zero-shot classifiers.
Keywords: auto-taxonomization, data modelling, knowledge graphs, SPARQL, data quality, machine learning, data visualization
Alena Vasilevich is a computational linguist at Coreon and Coreon's goal is to tackle problems and find solutions that would help taxonomists jobs a bit easier such as making a whole haystack of concepts and organizing them into an ordered graph. The video talks about the benefits of Collaborative-AI Approach and how it could be used in a case scenario where taxonomy can help leverage the company showing the benefits of collaborative AI vs. manual creation of ordered graph. #knowledgegraphs #knowledgegraphconference #knowledgegraphmachinelearning #knowledgegraphai
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
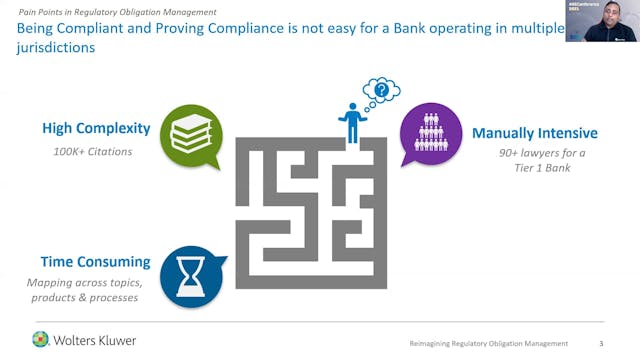
Abhishek Mittal | Re-Imagining Regula...
Content Enrichment: Development and deployment of a 5-stage taxonomy. Applying the taxonomy to tag regulations and classify them for improved discovery & work assignment.
Smart Authoring: Leveraging advanced NLP and ML techniques to learn from the past content authoring for identification of ... -
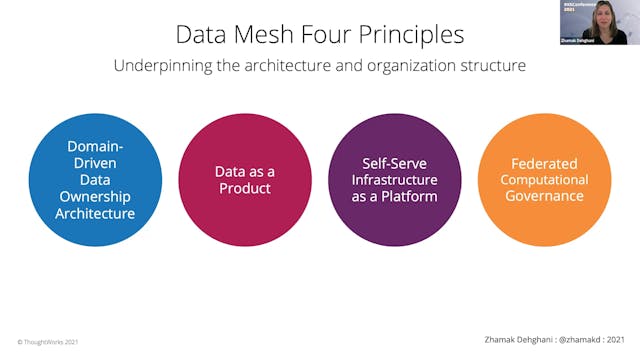
Zhamak Dehghani | Introduction To Dat...
For over half a century organizations have assumed that data is an asset to collect more of, and data must be centralized to be useful. These assumptions have led to centralized and monolithic architectures such as data warehousing and data lake, and neither of which have been able to enable data...
-
Andreas Blumauer | The Semantic Conte...
Ambiguity, language discrepancies, and lack of background information are just a few challenges that organizations face on a daily basis when trying to analyze their content and data. When an organization produces data that is hard to manage, what methodologies can be used to turn unstructured (i...