Shekhar Iyer | Multi-Modal Retrieval Over Knowledge Graphs
KGC21 | Conference Only Pass
•
24m
Recent Advances in representation learning and application of Deep Neural Nets towards structured data and Knowledge Graphs (KG) is enabling opportunities for multi-modal representation of entities and relations. We can now aspire to build access to data encoded in knowledge Graphs through one of many modalities (image, audio, text or video) and also train joint representations to cross over from one modality to another (e.g. text-to-image, audio-to-text). These kinds of capabilities allow us to build applications that can use entity information in entirely new ways, to exploit the sensors available in modern multi-modal devices like glasses, watches, smart earphones etc... These contextually aware smart devices provide a better model for the users to interact with the world and consequently need a more robust support from a multi-model knowledge Graph to help them contextualize the users environment. In this presentation I will talk about a retrieval architecture to support a multi-modal KG. I will also show some examples of prototypes we have built to multi-modal retrieval.
Up Next in KGC21 | Conference Only Pass
-
Ridho Reinanda | Financial Knowledge ...
The Bloomberg Knowledge Graph is a graph-centric representation of entities and relationships in the financial world which connects cross-domain data from various sources within Bloomberg. Recent developments in machine learning, knowledge graphs, and language technology have enabled intelligent ...
-
Melliyal Annamalai | Developing Enter...
Application developers often need to work with a variety of data types, data models, and workloads within an application. Oracle Database is a multi-model, multi-workload data platform with model-specific tools and technologies, enabling developers to build integrated applications while taking a...
-
Amgad Madkour | Entity Life Cycle In ...
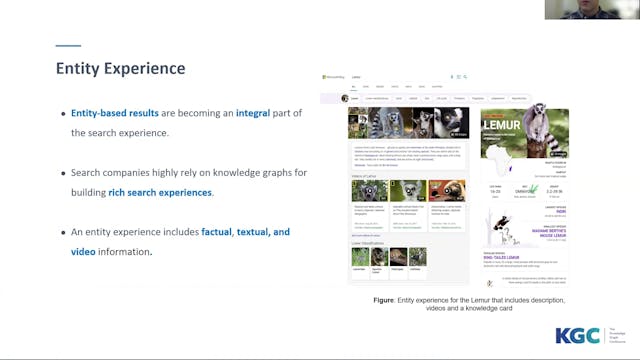
Entity-based results are becoming an integral part of the search experience. Search-centric companies highly rely on knowledge graphs in providing the necessary information for building rich search experiences. An entity can originate from a structured, semi-structured, or unstructured data sourc...