Ryan Wisnesky | How To Optimally Merge Knowledge Graphs With Category Theory
KGC21 | Conference Only Pass
•
19m
In this talk we describe a new technique for merging knowledge graphs: translating the knowledge graph schemas into categories and the knowledge graph data into functors, then applying the "co-limit/pushout" construction from a branch of mathematics called category theory to merge these categories and functors, and then converting the categories and functors back into knowledge graph schemas and data. We show how this process is mathematically optimal (results in the highest possible data quality in the merge), and describe several real-world use cases of knowledge graph merge that have been implemented in an open-source tool.
Up Next in KGC21 | Conference Only Pass
-
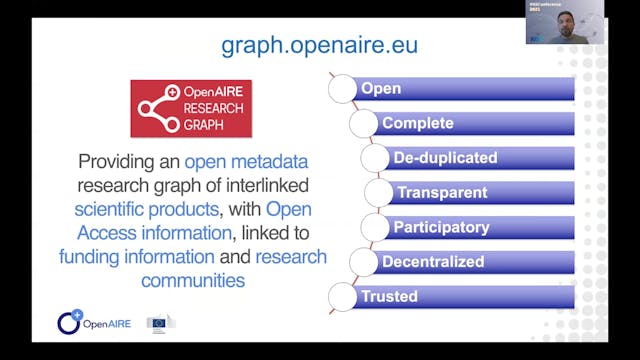
Paolo Manghi | The OpenAIRE Research ...
The presentation will introduce the motivations, architecture, and operation of the OpenAIRE Research Graph (http://graph.openaire.eu), one of the largest (if not the largest) public, open access, collections of metadata and semantic links (~1Bi) between research-related entities: articles (124M+...
-
Alena Vasilevich | Benefits Of Collab...
In the realm of data-driven businesses, structured data, being highly organized and easily understood by machines, is a valuable resource. IATE, with almost one million concepts storing multilingual terms and metadata, holds a large part of the textual knowledge of the EU. However, it can only be...
-
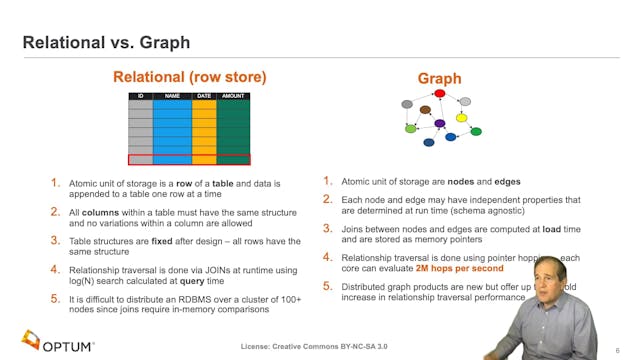
Dan McCreary | Graph Hardware Is Coming!
In this presentation we will show how current general-purpose CPU hardware fails to deliver high performance graph analytics. We show that by doing a detailed analysis of the actual hardware functionally needed by graph queries (pointer jumping), we can redesign hardware that is optimized for fas...