Chen Zhang & Dmytro Dolgopolov | Entity Disambiguation With Knowledge Graph
KGC21 | Conference Only Pass
•
21m
During the presentation, we will share our experience in building a knowledge graph leveraging Spark, NLP, and Machine Learning. We will start with explaining the business problems and challenges. Then walk through our data pipeline, including text analytics processes, name similarity solutions, street address normalization, clustering algorithms, confidence level building, etc. At the end we will discuss the business impact and the takeaways.
Dmytro Dolgopolov and Chen Zhang from FINRA, a company that protects investors controlling massive amounts of data as they can run up to 50,000 compute nodes per day and they process up to 135 billion market events per day. This talk will mainly talk about the knowledge graphs that they use are FINRA which are mainly enterprise search and using higher level analytics. In order to explain it, speakers talk about the Entity Disambiguation with Knowledge Graphs where data is extracted from an entity, then they link entity to entity. After linking, clusters are built of these entities and then these clusters allow disambiguation graphs to form which help identify unique entities. Dmytro will give Chen the mic and she provides an insight to these steps and list obstacles they had to overcome to create a system like this. #knowledgegraphs #knowledgegraphconference #knowledgegraphbigdataprocessing #knowledgegraphbusiness
Up Next in KGC21 | Conference Only Pass
-
Andreas Blumauer | The Semantic Conte...
Ambiguity, language discrepancies, and lack of background information are just a few challenges that organizations face on a daily basis when trying to analyze their content and data. When an organization produces data that is hard to manage, what methodologies can be used to turn unstructured (i...
-
Jan Hidders | A Report From The Prope...
The Property Graph Schema Working Group (PGSWG) is an informal working group that was set up in 2018 under the umbrella of LDBC, the Linked Data Benchmark Council, to support the formal working group that works on the SQL/PGQ and GQL, the upcoming ISO/IEC standards for managing property graphs. T...
-
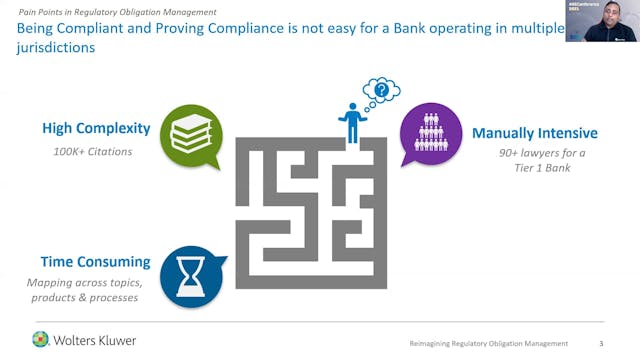
Abhishek Mittal | Re-Imagining Regula...
Content Enrichment: Development and deployment of a 5-stage taxonomy. Applying the taxonomy to tag regulations and classify them for improved discovery & work assignment.
Smart Authoring: Leveraging advanced NLP and ML techniques to learn from the past content authoring for identification of ...