Ryan Wisnesky | How To Optimally Merge Knowledge Graphs With Category Theory
KGC 2021 Conference, Workshops and Tutorials
•
19m
In this talk we describe a new technique for merging knowledge graphs: translating the knowledge graph schemas into categories and the knowledge graph data into functors, then applying the "co-limit/pushout" construction from a branch of mathematics called category theory to merge these categories and functors, and then converting the categories and functors back into knowledge graph schemas and data. We show how this process is mathematically optimal (results in the highest possible data quality in the merge), and describe several real-world use cases of knowledge graph merge that have been implemented in an open-source tool.
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
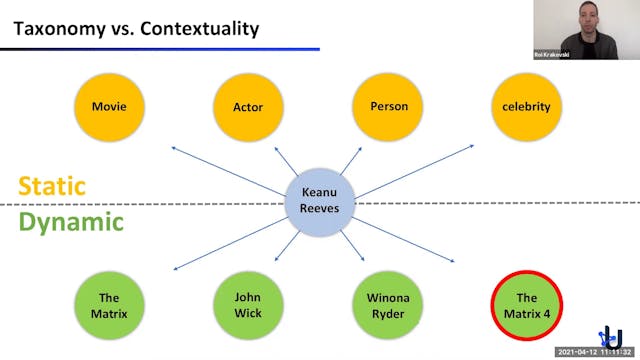
Roi Krakovski | The Usearch Contextua...
We exploit the recent breakthroughs in Neuroscience to build web search engines based entirely on AI-generated data, thus eliminating the need to collect users’ data. We show how to generate search queries that are almost identical to real users’ queries. We use the generated queries to build a ...
-
Ridho Reinanda | Financial Knowledge ...
The Bloomberg Knowledge Graph is a graph-centric representation of entities and relationships in the financial world which connects cross-domain data from various sources within Bloomberg. Recent developments in machine learning, knowledge graphs, and language technology have enabled intelligent ...
-
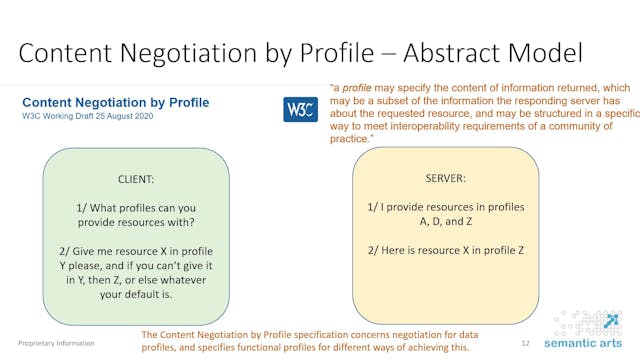
Peter Winstanley & Boris Pelakh | W3C...
This presentation will introduce and detail the current work of the W3C Dataset Exchange Working Group, including detail of the developments in the DCAT (Data Catalog) vocabulary and the proposal for content negotiation by profile (ConnegP) which is being developed by the working group in conjunc...