Mike Welch | Serving A Web Scale Knowledge Graph
KGC 2021 Conference, Workshops and Tutorials
•
19m
The Yahoo Knowledge Graph powers entity data for user experiences across multiple products at Verizon Media, from search to media to ads. Nodes in the knowledge graph correspond to real world entities: people, places, movies, sports teams, and so on. The edges represent semantic relationships between these entities. A comprehensive entity experience requires collecting a use-case specific subgraph around an entity node in the graph and combining it with dynamic and multimedia content.
A "knowledge panel" for a public company on a web search results page might include basic data like the company's founders and number of employees, combined with a realtime stock quote and relevant images. Other use cases, like a finance-focused website, may prefer to include additional detailed information like the board members, other companies those board members represent, revenue numbers, top competitors, and more. Legacy serving systems typically pre-collected and exposed a static view of an entity, which limited the ability for clients to traverse the graph or adapt the user experience for different contexts without offline preprocessing. They also required clients to implement a more complex series of requests to fetch partial data, extract dependencies, and query additional services to stitch together their full experience.
In this talk we will take you through our experience moving away from serving these static subgraph views with independent services and client side processing. We will describe how we addressed the shortcomings of such a system and built a federated, realtime, web-scale graph querying framework with GraphQL on top of Amazon Neptune, Vespa, and third party APIs. Our unified graph approach has enabled customer teams to experiment, rapidly iterate over their designs, and easily power rich experiences by bringing together all the relevant data under a single request.
Up Next in KGC 2021 Conference, Workshops and Tutorials
-
Mike Tung | Automated Knowledge Graph...
Nearly every business is constantly trying to identify, analyze, and grow their market. Yet, traditional processes for data management inevitably lead to a database that contains missing, outdated, invalid, or inconsistent data. Automated knowledge graph construction techniques are a scalable w...
-
Michael Cafarella | Infrastructure Fo...
Social Knowledge Graphs such as Wikidata have become massive successes, obtaining a level of coverage and quality that would be the envy of many traditional relational database engineering projects. And yet the downstream use scenarios for such datasets remain sharply limited compared to the vast...
-
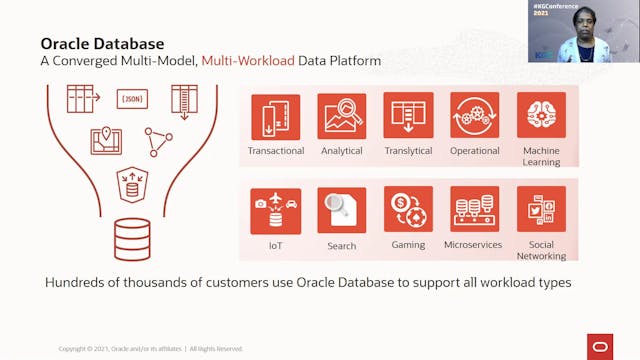
Melliyal Annamalai | Developing Enter...
Application developers often need to work with a variety of data types, data models, and workloads within an application. Oracle Database is a multi-model, multi-workload data platform with model-specific tools and technologies, enabling developers to build integrated applications while taking a...