Mark Grover | From Discovering To Trusting Data
KGC | All Access Subscription
•
23m
Over a third of analyst time is spent in understanding what data exists, can it be trusted and how to use it. Countless Data Engineering time is spent in answering the same questions about data - what does that column mean, how does it get populated, how often does it update and if there’s any incident going on?
The answer thus far to such questions has been curation. You request volunteers to put in this information or hire project managers to make sure it does but it always fails because documentation gets out of date. The holy grail to solving this is automation - collecting metadata automatically from various data sources and creating a rich graph - of data sets, reports, humans, jobs, streams, event schemas and more. Then build opinionated products on top of it to deliver a better experience for data users.
At Lyft, we have made our analysts and data scientists over 20% more productive by making it easier to discover data. Recently, we open sourced Amundsen and it’s now being used by ING, Square, Workday and many more.
However, as we made it easy to discover data, it’s led to an interesting challenge. Not only is it now easy to discover good trusted data, it’s also easier to discover bad data that was previously hidden in the unforgotten nook and crannies of the data lake. Consequently, we are now asking ourselves, how can we recommend not just any data but trusted data to our users.
This talk gives a quick overview of Amundsen and then goes into detail on how we have tried both automated and curated metadata to showcase what’s trusted and not in Amundsen. It will dive deep into linking the Airflow DAG which produced the data (task level lineage), linking what and how many dashboards are built from a given data set (table level lineage), as well as SLAs and historical landing times to give users signal into what’s trusted.
The talk will end with an insight into current challenges and how we may solve them in the future.
Trusting data is very difficult to do in this day and age according to Mark Grover from Stemma.AI. The issue Mark presents today is that current workflow requires establishing that data is valid mainly through discovery and the exploration of the data which takes a lot of time due to understanding of the unstructured data and forming it into something they could use. Mark goes over how this trusting of data became a problem over the last few years. He will then proceed to present possible solutions to the problem at hand such as making it exposed in a user friendly way. Mark will introduce goals such as reducing time to find trusted data through the use of versatile graphs and present Amundson which is a search page which will help search and find data which will help the workflow for people such as a new employee or data scientist searching for information within the data resources. #knowledgegraphs #knowledgegraphconference #knowledgegraphuses #knowledgegraphsdataincontextforresponsivebusinesses
Up Next in KGC | All Access Subscription
-
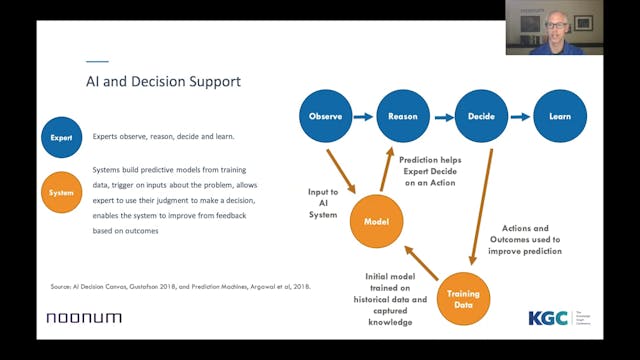
Steven Gustafson | Connecting The Dot...
Knowledge graphs provide a way for us to capture and relate information into a representation that can mimic expert knowledge. One type of expert knowledge that has proven to be particularly useful in industry is reasoning by analogy, or using a replacement problem and solution pair to think abo...
-
Martynas Jusevicius | Data-centric Tr...
One of the key pieces of global infrastructure today is the web yet it continues to be developed using legacy technologies dating back to the 1960s. A result of using outdated technology in turn has created several major problems. First, relational data models are a primary contributor to the dat...
-
Alex Kalinowski | Structured To Unstr...
Identification of entities and the relations between them is a difficult task for traditional pattern-based matching or machine learning approaches; these techniques rapidly overfit training datasets and struggle to transfer to other contexts or domains. Utilizing outside knowledge, such as facts...