Ben De Meester | PROV4ITDaTa: Flexible Knowledge Graph Generation Within Reach
KGC 2021
•
16m
Personal Knowledge Graph generation is no longer a cumbersome technical endeavor. PROV4ITDaTa is an MIT open source platform to provide a smooth user experience for generating knowledge graphs from your online web services, such as Google, Flickr, and Imgur, into your personal data space. This brings your personal data back under your control, and as a graph, its true interlinking potential is unleashed. PROV4ITDaTa allows to configure and set up a web application where users can easily pick one or more web services to extract their data from, transform that data into best-practice knowledge graphs, and push those graphs to a personal data space, such as a Solid pod.
All heavy lifting is included in PROV4ITData: management of service authentication (e.g., OAuth 1.0/2.0 sessions), setting up the infrastructure to extract and transform your personal data from popular web services, directly loading those graphs into your personal data space, and generating a simple user interface. Developers only need to focus on providing custom connectors to more specialized web services, and configuring the data processing pipeline to generate knowledge graphs into any needed form or shape.
The data processing pipeline is based on RML.io, meaning that it is extensible to any data source, can integrate multiple data sources on the fly, includes data cleansing functions, supports any RDF graph structure and ontology, and its configuration is fully declarative. The pipelines are thus more maintainable and more transparent than hard-coded solutions such as the Data Transfer Project (DTP). Where existing platforms such as DTP provide one-to-one data transfer, PROV4ITDaTa enables extensible many-to-many data processing pipelines, beyond the web services and (personal) data spaces we currently provide. All these features can easily be included in the PROV4ITDaTa platform, and will be showcased during the presentation.
As a result, developers can more easily support custom web services. As users can generate personal knowledge graphs faster and easier, more knowledge graph applications can be built that rely on real-world data. With a click of a button, users can try out knowledge graph applications using their actual data from music streaming systems, fitness apps, address books, social media, etc.
Continuing this product, we are building a data processing workbench, where these different data processing pipeline configurations can be managed, scheduled, and orchestrated, giving companies more control, and allowing to upscale PROV4ITData more easily.
Introducing PROV4ITDaTa is Ben De Meester, a postdoctoral researcher at IDLab. In this talk he provides insight on the problems with current data that is messy and personal.Data is scattered across several service providers and is difficult to transfer over. The solution he provides is PROV4ITDaTa, an open source flexible tool for transparent and direct transfer of personal data to personal stores. He discusses mainly about PROV4ITDaTa explaining how it could knowledge scientists and allow users to easily transfer their data using PROV4ITDaTa. #knowledgegraphs #knowledgegraphconference #knowledgegraphtools #knowledgegraphandbigdataprocessing
Up Next in KGC 2021
-
Bernhard Krabina | Semantic MediaWiki...
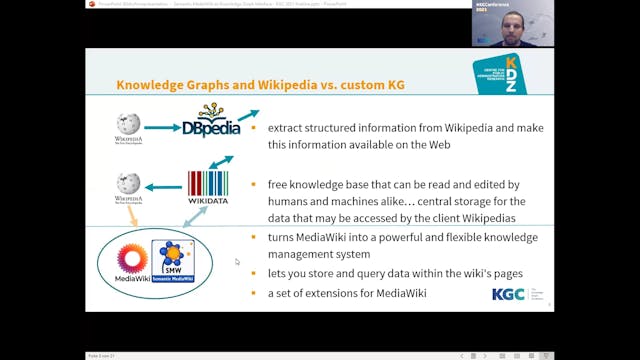
Semantic MediaWiki (SMW), which was introduced as early as in 2006, has since gone on to establish a vital community and is currently one of the few semantic wiki solutions still in existence. SMW is an extension of MediaWiki, the software used for Wikipedia and many other projects, resulting in ...
-
Johannes Keizer | VocBench: A Semanti...
This presentation will feature and demonstrate "VocBench", an semantic web collaborative development platform for ontologies, thesauri and lexicons.
VocBench has initially been developed for maintenance of the thesaurus "Agrovoc". It has become then a generic tool for thesaurus management and now... -
Paco Nathan | Graph Based Data Science
Python offers excellent libraries for working with graphs: semantic technologies, graph queries, interactive visualizations, graph algorithms, probabilistic graph inference, as well as embedding and other integrations with deep learning. However, most of these approaches share little common groun...